Why AI Learns in Three Powerful Ways
How machines really figure things out
5 min readNagaraj
The moment I stared an AI model in the face, I questioned, “Why is this so hard?”
You are not in doubt. You just have too much information.
So was I.
I have the memory of one sitting in front of a dataset, a completely misshaped one, and a question that would go on reiterating in my brain, very hard: “Learning? What is even learning for this AI?”
That one question completely shattered my self-confidence for weeks. And then all of a sudden it just clicked.
AI does not learn in a single manner. It learns in three, with each learning process aimed at a different type of suffering.
As soon as you get that, the fog is gone.
Supervised Learning — When the Answers Are Known
The right or wrong answer given feel like very safe to you.
In the same way, AI feels.
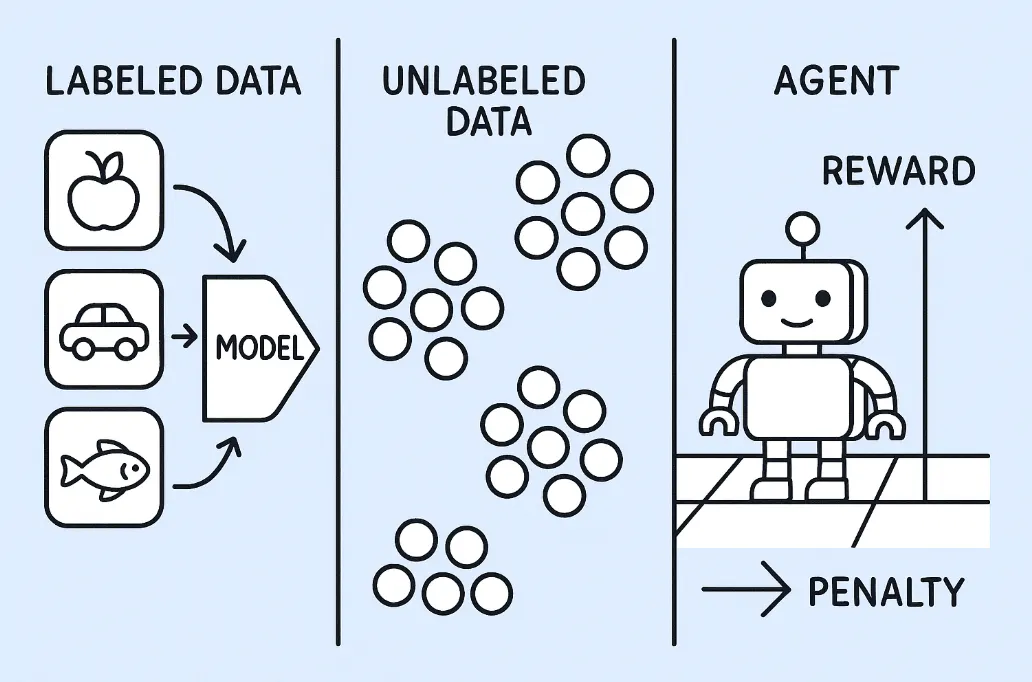
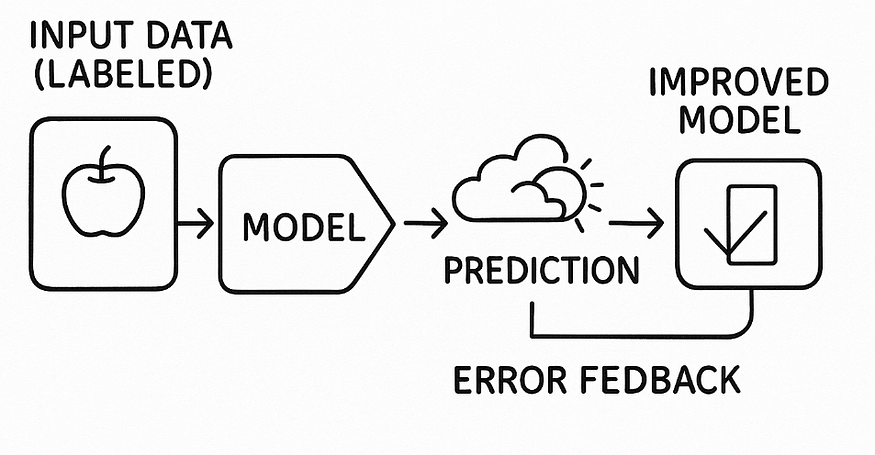
Supervised learning utilizes the data that is already confirmed as the truth and works perfectly. Images tagged, Prices recorded, and Outcomes defined.
The model won’t be making the blind guess. It will be learning through correction.
One was this was what was the realization for me: Supervised learning is like a guided repetition.
How does it work on the ground?
- The data going in has labels
- The model gives the output
- The prediction is contrasted with the known answer
- The model is reshaped by the mistake
This is the reason why image classification and price prediction seem “easy” once the data is labeled.
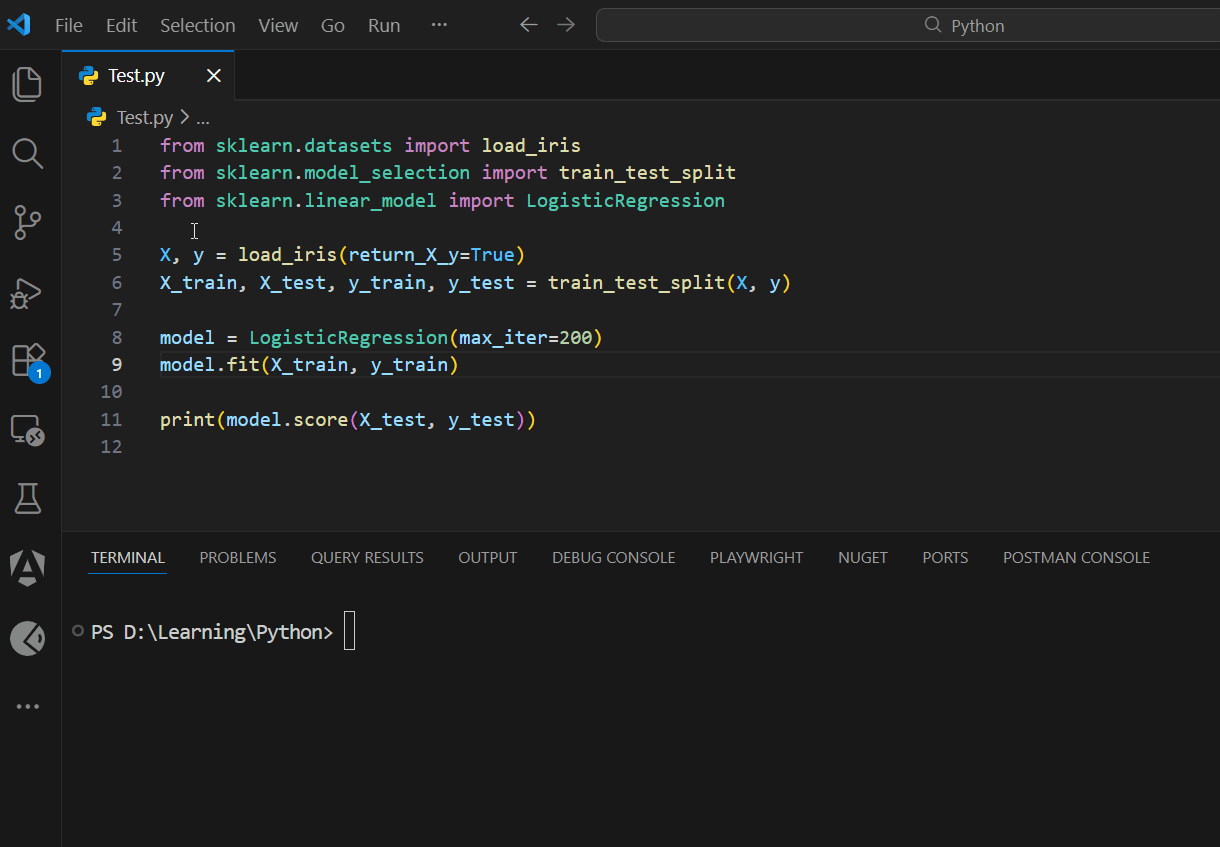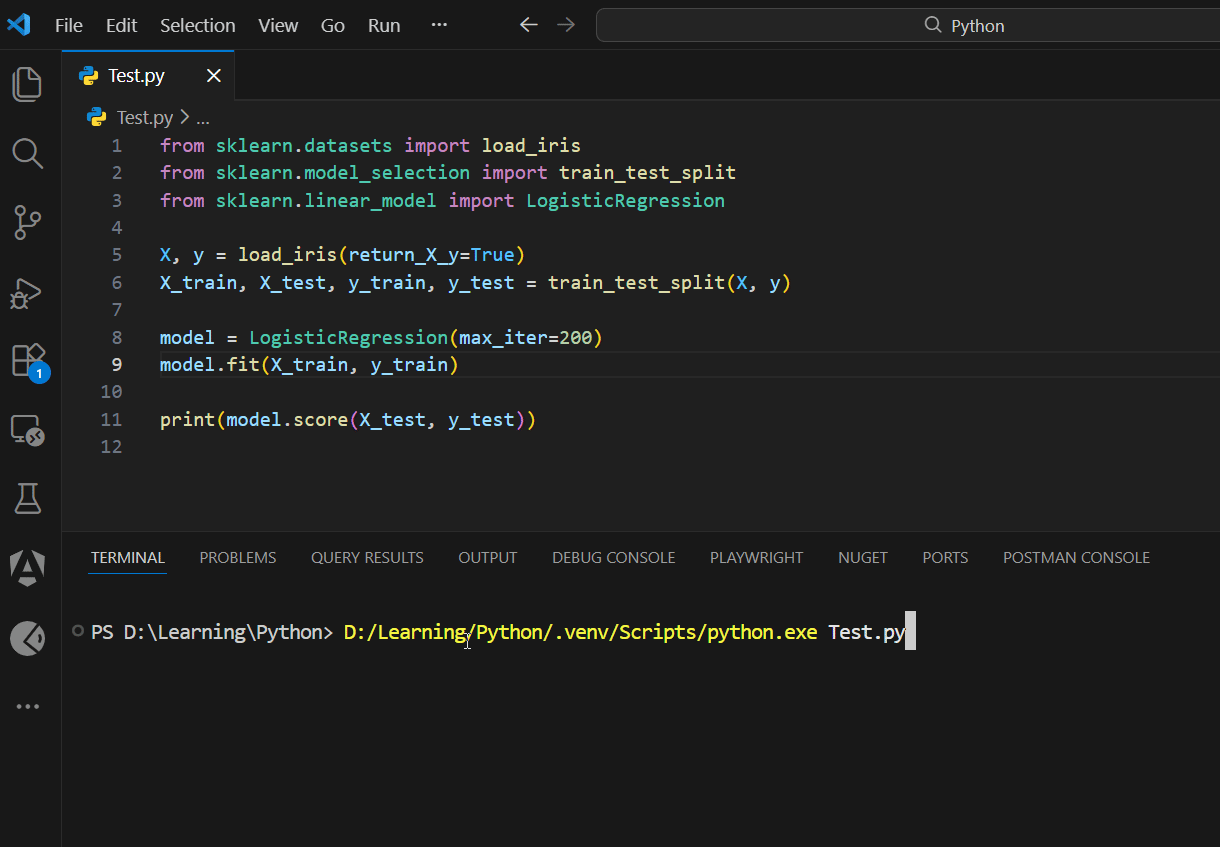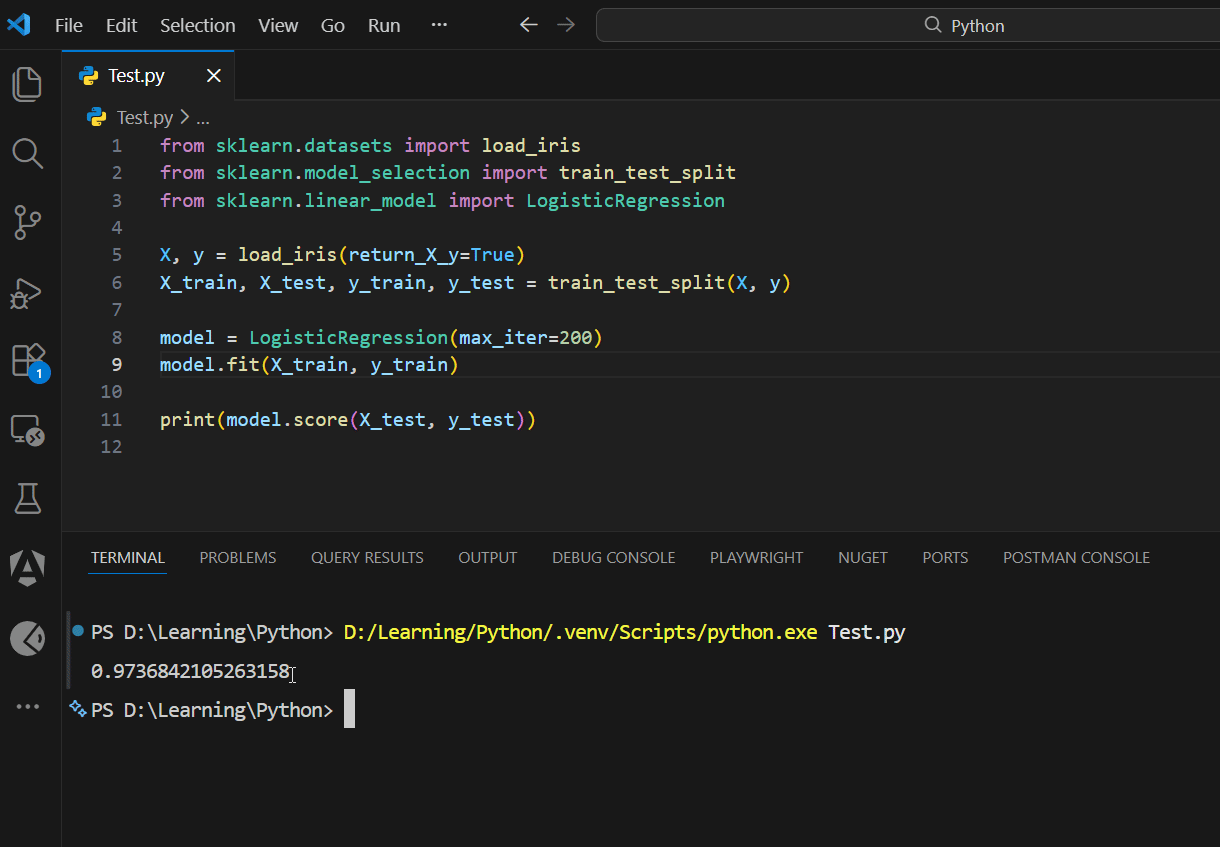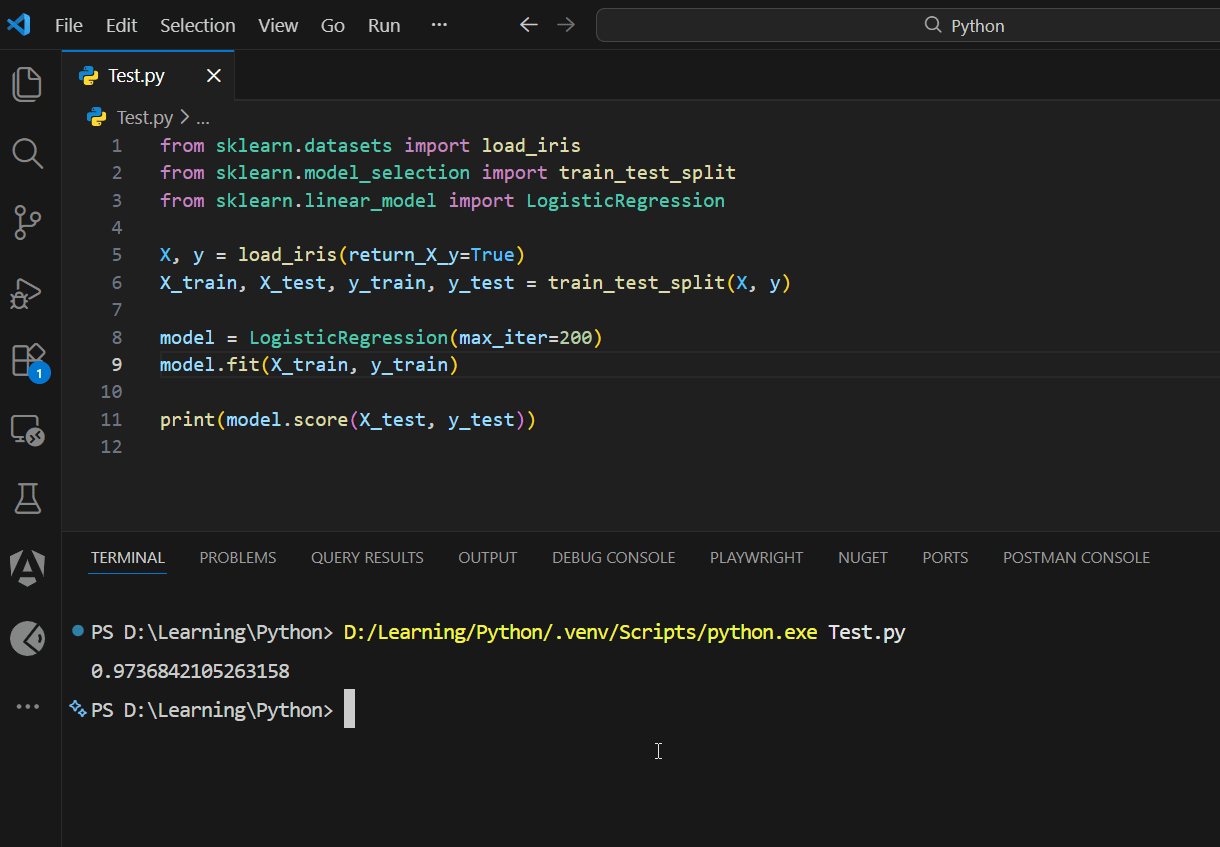
Classification
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
print(model.score(X_test, y_test))
You are not teaching the intelligence. You are just correcting mistakes at a huge scale.
- The labels work as guardrails
- The feedback is instant
- The accuracy rises with the iterations
The learning is made faster with the clarity.
Unsupervised Learning — When Patterns Hide in Plain Sight
At this point, I was completely confused.
I had no labels to work with, no clues to guide me, and no definite solutions.
All I could do was to face the raw data that was there.
Unsupervised learning does not pose the question of “Is this correct?” It rather inquires “What is alike?”
That change of the question made everything different.
What’s really happening
- Data comes in without any labels
- The model looks for patterns in the data
- Items that are similar get combined in one group
- A network of relationships forms without any intervention
The model does not have a clue about what the group means. It only knows that there are some patterns.
This is a great power when you have no idea what to search for.
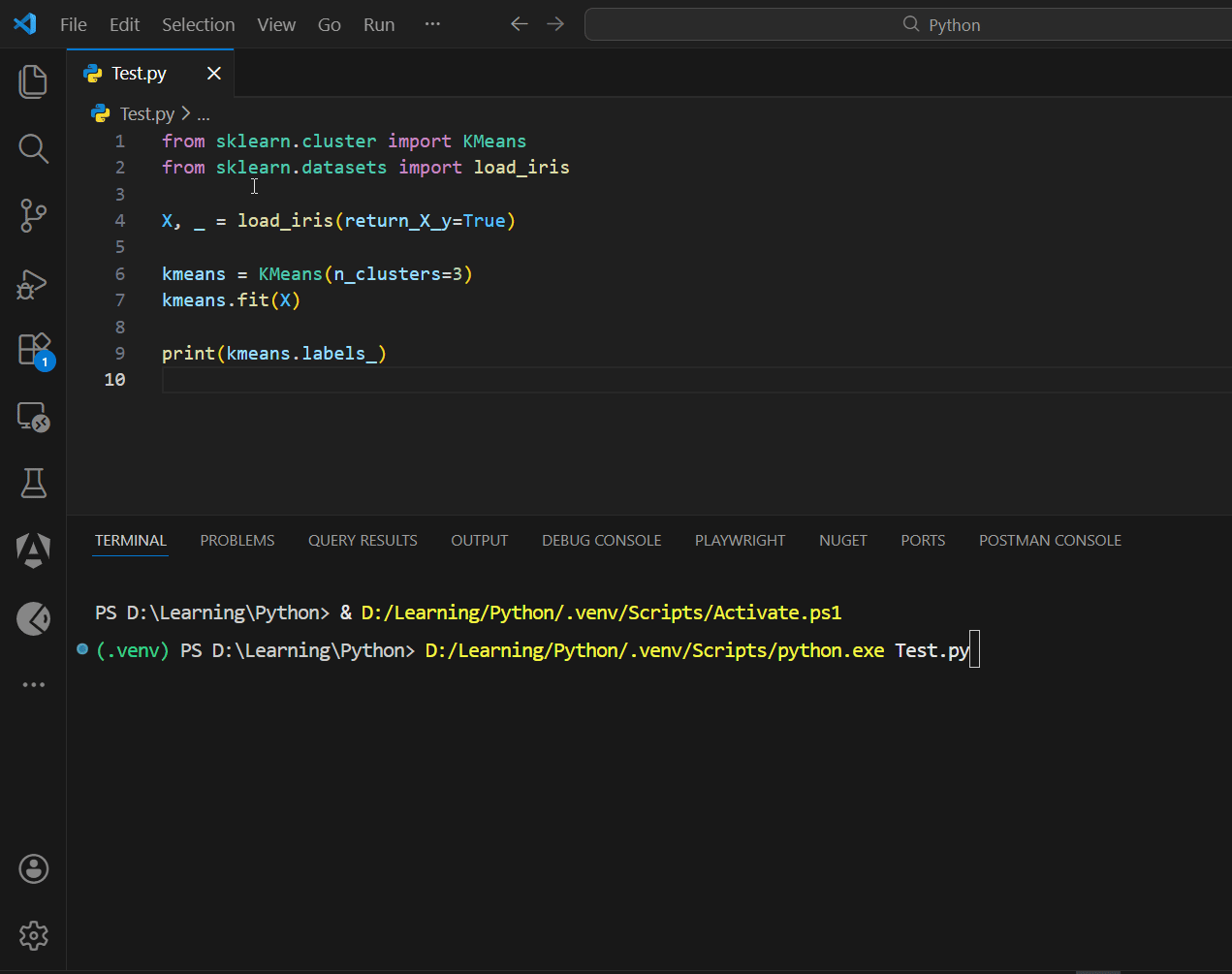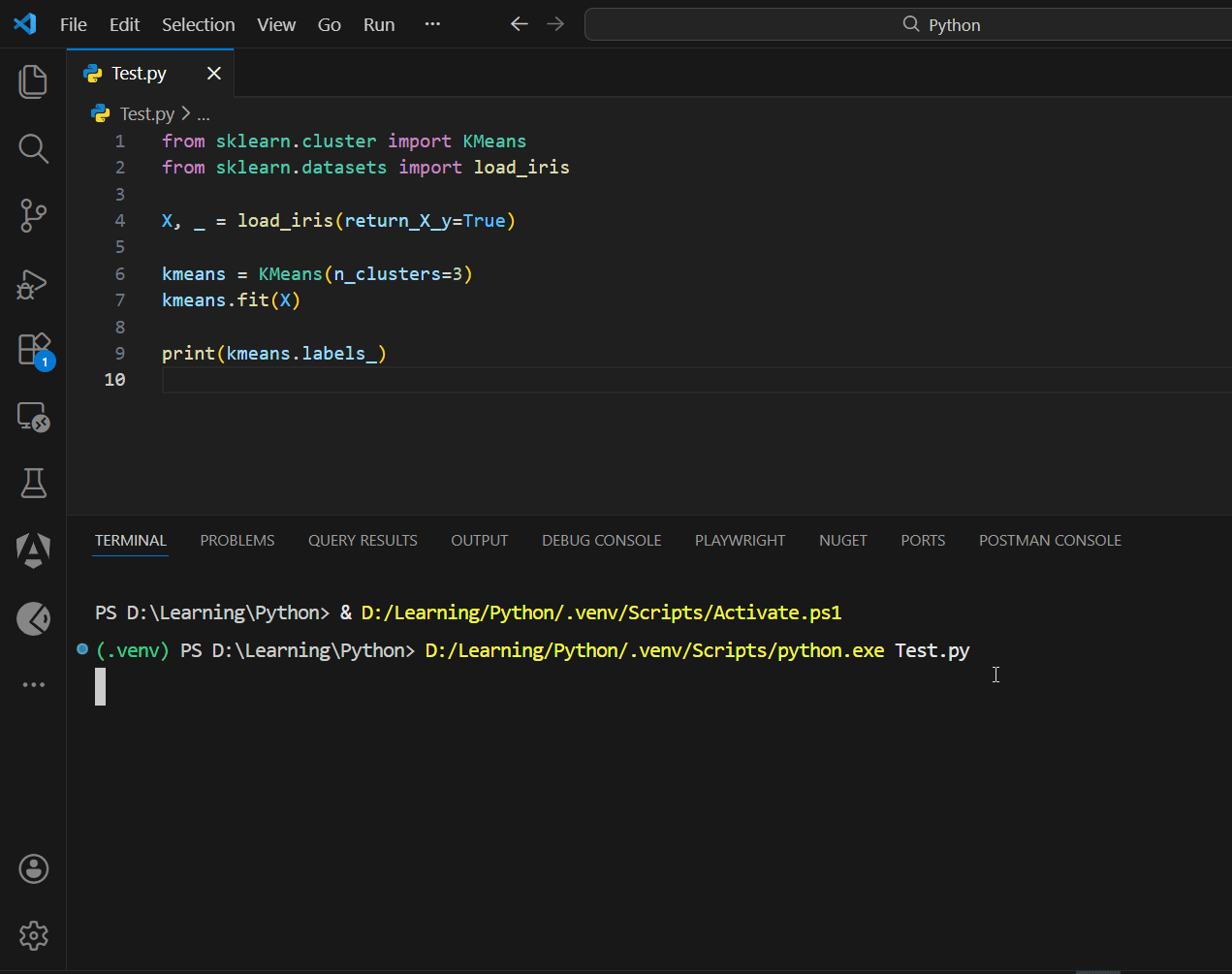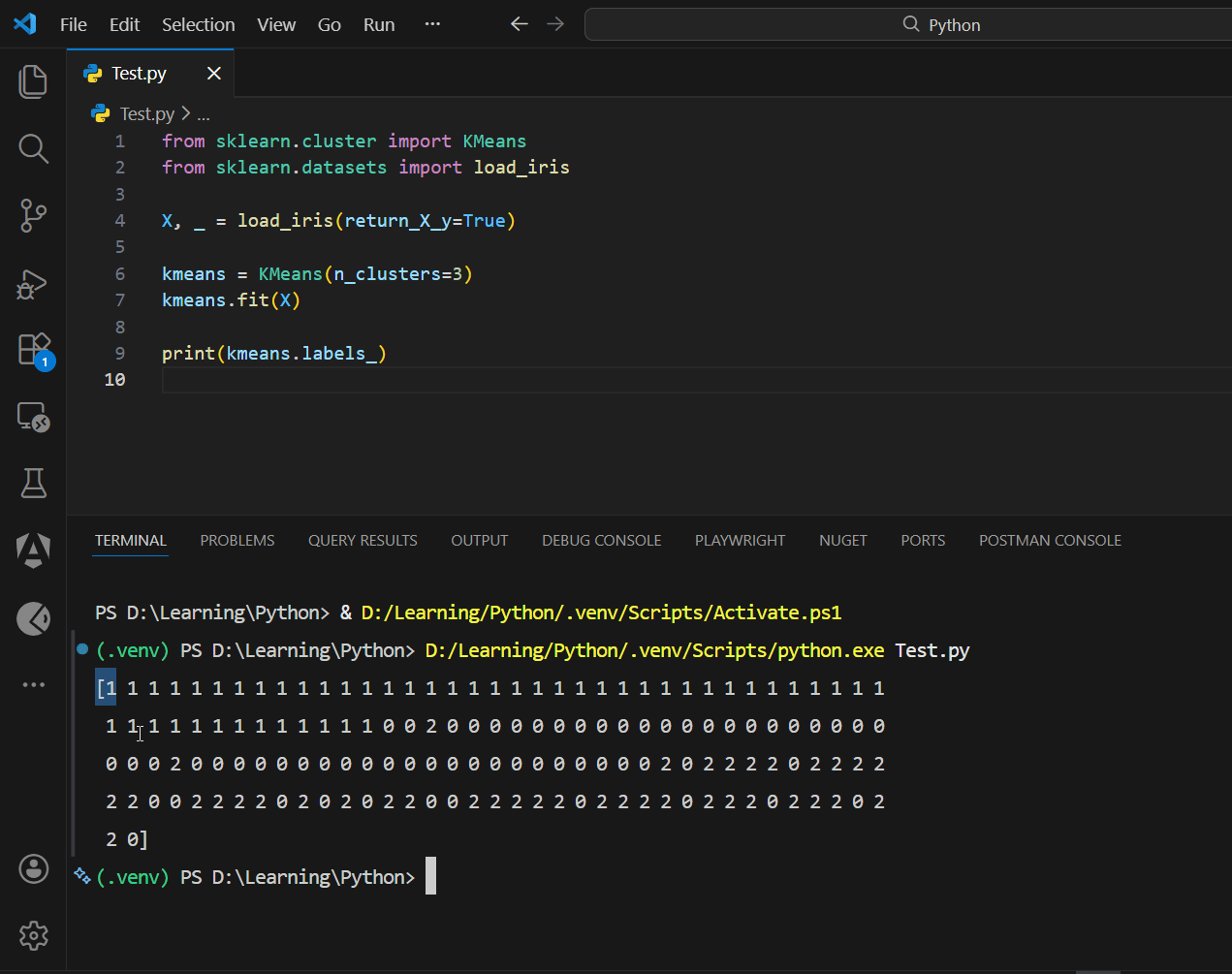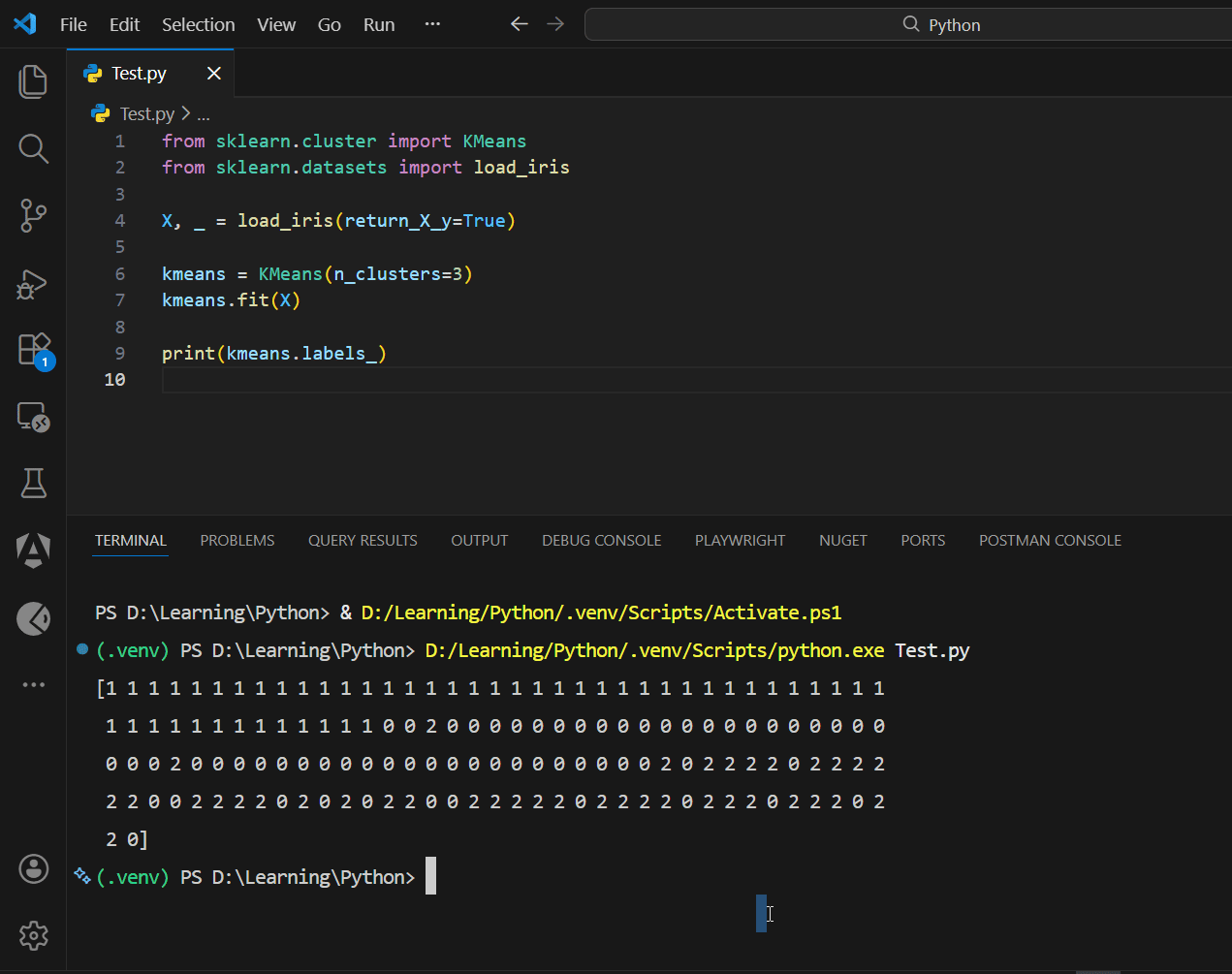
Practical demo (clustering)
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
X, _ = load_iris(return_X_y=True)
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
print(kmeans.labels_)
This is how machines make the following discoveries:
1. Customer segments 2. Image similarities 3. Hidden behavioral groups
No help was given. Only the structure was provided.

The emergence of patterns is due to the cessation of imposing answers.
Reinforcement Learning — Learning through Consequences
The first time I encountered this concept, it was a hard nut to crack for me.
No annotations. No demonstrations. Only an objective.
Reinforcement learning is challenging because it is a precise reflection of life.
You do something. You make a mistake. You change your approach.
The algorithm acquires knowledge via a mix of reward and punishment rather than direct teaching.
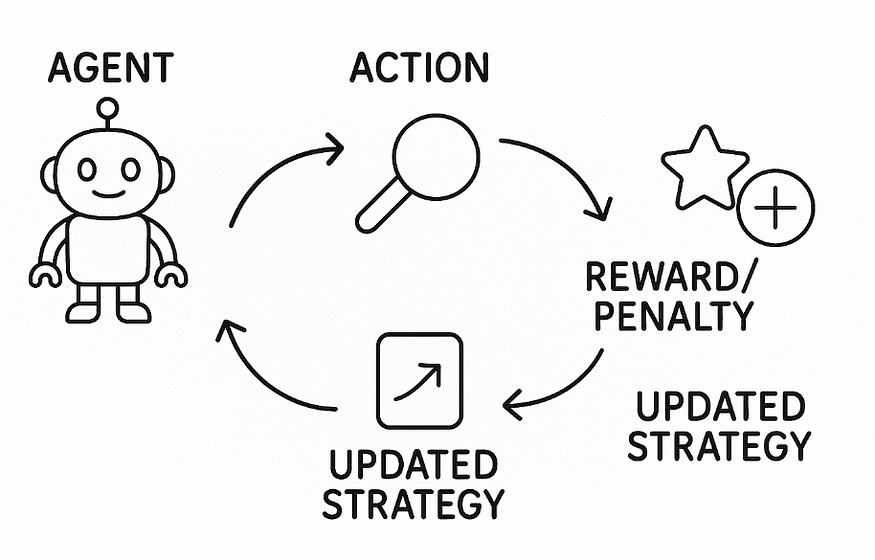
The main cycle
- The agent performs a move
- The environment reacts
- A reward or penalty is issued
- The agent learns
No teaching is provided. Only learning takes place.
That’s why it is very effective in dealing with systems that are constantly changing.
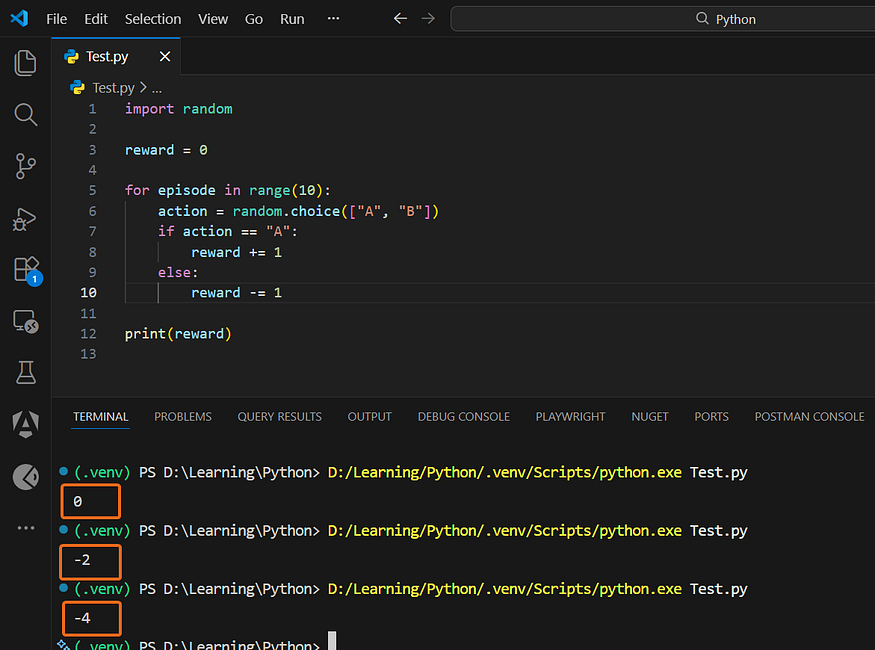
A very basic intuitive demonstration
import random
reward = 0
for episode in range(10):
action = random.choice(["A", "B"])
if action == "A":
reward += 1
else:
reward -= 1
print(reward)
This is very close to how recommendation systems grow:
- Actions take the place of labels
- Feedback takes the place of answers
- Consumption creates intelligence
The key point is not to be right once. The key point is to improve every time.
Feedback, not guidance, is the source of progress.
Why These Three Exist Together 🧩
The hard truth I learned late is as follows:
One learning style applied to every single problem is self-defeating.
All methods are for a reason and the reason is that reality is complicated.
- Different situations bring different answers;
- Different times make different answers;
- Different situations may even make the wrong answers be the right ones.
AI learns the same way because learning is like that.
And as soon as you quit to impose the wrong method, the whole thing becomes easier.
Learning via the right method is resistance-free.
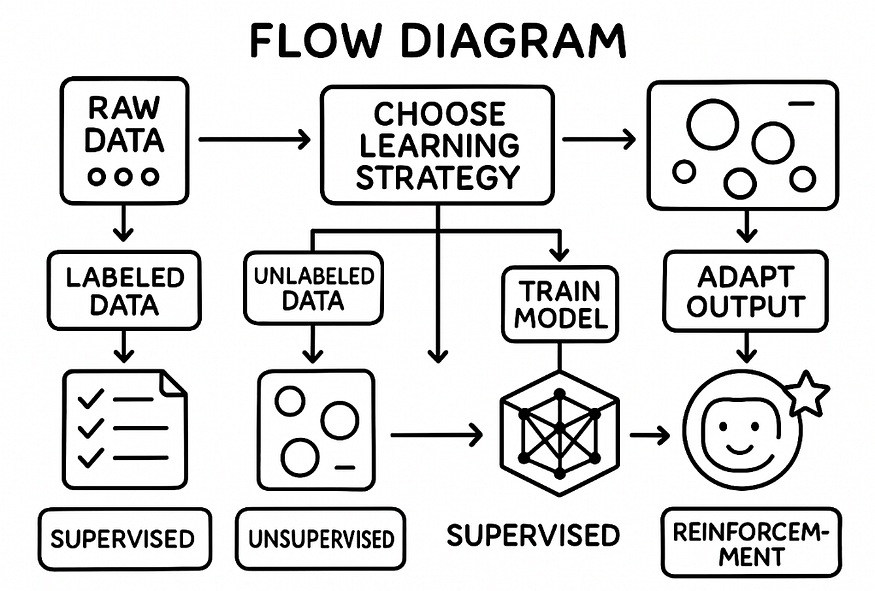
When to choose which learning method???
🔚 End of topic
If only I had known this sooner:
Your AI skills are not that poor. It was just the learning lens that was not suitable.
When you match the issue with the way machines understand, AI no longer seems like magic and starts to be very useful.
And that is the moment when actual development commences.
Thank you for reading!
More in artificial-intelligence



Cubed
Write about the technologies shaping the future.
For developers, founders, and curious minds exploring AI, crypto, Web3, and emerging tech—signal over noise.
One free account across In Plain English, Stackademic, Venture, and Cubed.
How it works- AI, crypto & Web3
- Software & emerging technologies
- Analysis & practical resources
- Thoughtful voices, not hype
Sign in
Google or GitHub
Complete profile
Takes a few minutes
Get approved & publish
Start sharing
Why write for Cubed?
The future deserves thoughtful voices, not just louder headlines.


Comments
Loading comments…