When You Don’t Need an AI to Grade Your AI
10 min readChamara Vishwajith

The old-school metrics are faster, cheaper, and sometimes better than LLM-based evaluation.
Series: Stop Vibing, Start Evaluating-Part 4 of 5
Catching up? Part 1 — Why vibe checks are killing AI products. Part 2 — The 6 RAG metrics that tell you where your AI breaks down. Part 3 — How to evaluate AI agents that take actions. This one stands on its own but the series makes more sense read in order.
Here’s something nobody tells you when you start building AI apps.
You don’t always need another AI to evaluate your AI.
Every metric we’ve covered so far uses an LLM (Large Language Model — the AI that generates text) as a judge. That’s powerful. But it’s also slow, expensive, and occasionally wrong. Sometimes the best tool for the job is a dead-simple formula that runs in milliseconds and costs exactly nothing.
These are the traditional NLP metrics. They’ve been around for decades. And in the right situations, they absolutely slap.
Story from the translation office

Immediately after the subheading “story from the translation office” and before the paragraph starting with “It’s 2003…”
It’s 2003. A translation agency needs to check whether their software is translating Spanish documents into English correctly. They have 10,000 documents to review. Hiring human reviewers for all of them would cost a fortune and take months.
So a researcher named Kishore Papineni builds a simple scoring system. He takes the machine translation, compares it word-by-word to a human-written reference translation, and counts how many words and phrases overlap. The more overlap, the better the translation. He calls it BLEU score.
It’s not perfect. It misses tone, context, and creative phrasing. But for catching obvious errors at scale, a word missing here, a phrase wrong there, it works remarkably well.
That little scoring system became one of the most widely used evaluation tools in all of natural language processing (the field of teaching computers to understand human language). And twenty years later, it’s sitting right inside Ragas, ready for you to use on your AI app today.
Aha moment: Traditional metrics don’t understand your text. They just compare it. And sometimes, that’s exactly enough.
Why would you choose these over LLM-based metrics?
Great question. Here’s the honest answer.
LLM-based metrics are smart but come with baggage. They’re slow — each evaluation needs an API call. They cost money; every call burns tokens. And they can be inconsistent, ask the same LLM judge twice, and you might get slightly different scores.
Traditional metrics have none of those problems. They run locally, in microseconds, for free. They give the exact same score every single time. No randomness. No surprises.
The tradeoff? They’re less intelligent. They can’t understand that “Paris is the City of Light” and “Paris is the capital of France” are both correct answers to “Where is Paris?”. They just count characters and words.
So here’s the rule of thumb: use traditional metrics when your answers are predictable and structured with exact dates, names, code snippets, tool arguments, and short factual answers. Use LLM-based metrics when answers are open-ended and nuanced explanations, summaries, and creative writing.
Under the section “Why would you choose these over LLM-based metrics?” specifically after the “Rule of thumb” paragraph.
Now, let’s meet the six traditional metrics Ragas gives you.
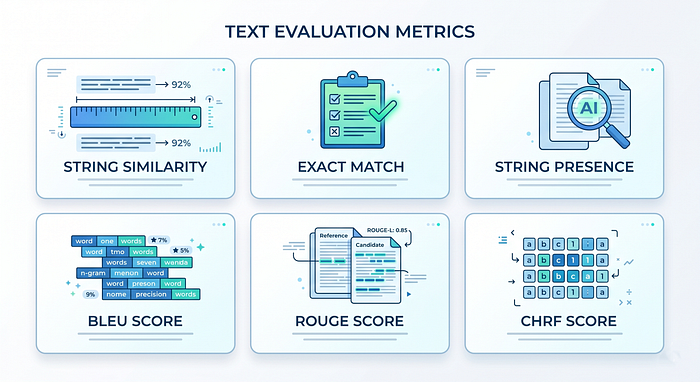
The 6 traditional metrics, explained simply
Right under the heading “The 6 traditional metrics, explained simply” to serve as a visual table of contents.
1. String Similarity — how different are the two texts, letter by letter?
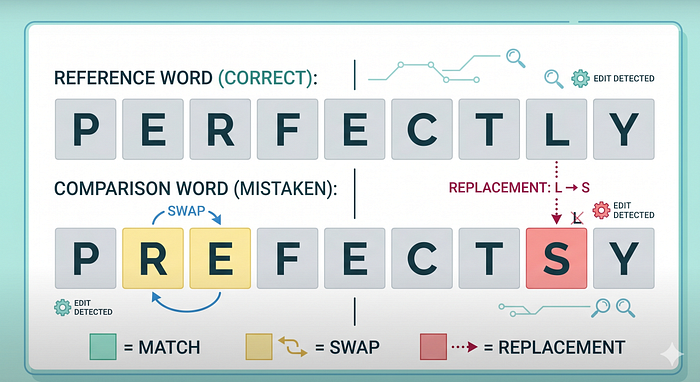
Imagine you’re a spell-checker. You see the word “recieve,” and you know the correct spelling is “receive”. You don’t understand either word; you just count how many letter swaps, insertions, or deletions it takes to turn one into the other. The fewer edits needed, the more similar they are.
That’s NonLLM String Similarity. It measures how close two pieces of text are using pure character-level math. Ragas gives you three flavours:
- Levenshtein distance — counts the minimum edits (insert, delete, swap a character) to turn one string into another. Great for typos and small variations.
- Hamming distance — only counts positions where the two strings differ, character by character. Only works on equal-length strings.
- Jaro / Jaro-Winkler — designed for short strings like names. Gives extra credit if the strings share the same starting characters.
from ragas.metrics.collections import NonLLMStringSimilarity, DistanceMeasure
scorer = NonLLMStringSimilarity(distance_measure=DistanceMeasure.LEVENSHTEIN)
result = await scorer.ascore(
reference="The Eiffel Tower is located in Paris.",
response="The Eiffel Tower is located in India."
)
# Score: 0.89 — texts are very similar, just one word different
A score of 0.89 here means the texts are 89% similar at the character level. One word changed “Paris” to “India,” but 89% of the characters are still the same.
“String Similarity”, specifically after the paragraph explaining Levenshtein, Hamming, and Jaro-Winkler.
2. BLEU Score — how many word patterns match?
Back to our translation office. BLEU (Bilingual Evaluation Understudy a name that basically means “AI stand-in for a human evaluator”) measures how many n-grams (chunks of consecutive words) in the AI’s response appear in the reference answer.
Think of it like this. Your friend describes a movie as “a thrilling sci-fi adventure with stunning visuals.” A critic writes “a visually stunning sci-fi thriller.” BLEU counts how many two-word or three-word phrases overlap between the two descriptions.
It also adds a brevity penalty, a deduction if the AI’s response is suspiciously short. This stops the AI from gaming the score by saying one correct word and nothing else.
from ragas.metrics.collections import BleuScore
scorer = BleuScore()
result = await scorer.ascore(
reference="The Eiffel Tower is located in Paris.",
response="The Eiffel Tower is located in India."
)
# Score: 0.71 — good n-gram overlap, but one key word is wrong
Best used for: machine translation evaluation, structured short answers, code generation.
3. ROUGE Score — how much of the reference made it into the response?
ROUGE (Recall-Oriented Understudy for Gisting Evaluation another mouthful of a name) was built for summarisation. The question it asks is slightly different from BLEU.
BLEU asks: “How much of the response matches the reference?” ROUGE asks: “How much of the reference made it into the response?”
It’s the difference between precision and recall (remember those from Part 2?). BLEU leans toward precision. ROUGE leans toward recall.
Imagine a student writes a summary of a 10-page article. You want to check if they captured the key points. You don’t just care whether their words are correct you care whether the important things from the original actually made it into their summary. That’s ROUGE.
Ragas gives you three ROUGE variants:
- rouge1 — matches individual words
- rougeL — matches the longest sequence of words that appear in both texts in the same order
- Modes: precision, recall, or fmeasure (the balanced F1 combination of both)
from ragas.metrics.collections import RougeScore
scorer = RougeScore(rouge_type="rougeL", mode="fmeasure")
result = await scorer.ascore(
reference="The Eiffel Tower is located in Paris.",
response="The Eiffel Tower is located in India."
)
# Score: 0.86 — most of the reference structure survived, one word is off
Best used for: summarisation, document comparison, checking if key information was retained.

Between the “BLEU Score” and “ROUGE Score” sections. This helps bridge the gap between “n-gram overlap” and “reference coverage.”
4. CHRF Score — BLEU’s smarter cousin for tricky languages
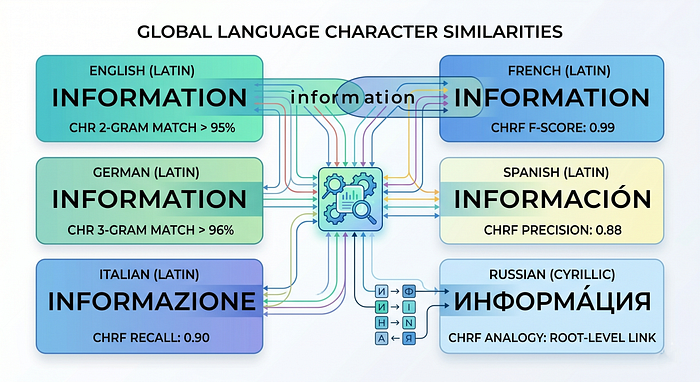
CHRF (Character n-gram F-score) is like BLEU, but instead of comparing whole words it compares chunks of characters. This makes a huge difference for languages like Arabic, Finnish, or Turkish, where a single word can have dozens of variations depending on grammar.
In English, “run”, “runs”, “running”, and “ran” are four different words. In some languages, all of those are the same root word with different endings. Word-level metrics like BLEU treat them as completely different. CHRF, working at the character level, recognises the similarity.
It also handles paraphrasing better. “The tower stands in Paris” and “Paris is where the tower stands” have very different word order but share a lot of the same characters and character patterns. CHRF catches that.
from ragas.metrics.collections import CHRFScore
scorer = CHRFScore()
result = await scorer.ascore(
reference="The Eiffel Tower is located in Paris.",
response="The Eiffel Tower is located in India."
)
# Score: 0.80 — character-level overlap is high despite the wrong city
Best used for: multilingual apps, morphologically rich languages, responses with flexible phrasing.
Place: Under “CHRF Score”, right after the paragraph explaining how English “runs/running” differs from morphologically rich languages.
5. Exact Match — is it exactly right?
This one needs no explanation. Either the response matches the reference perfectly, or it doesn’t. Score of 1 or 0. No in-between.
It sounds simple. But it’s actually incredibly useful for scenarios where partial credit makes no sense, like checking if a tool argument is exactly "New York" or if a date is exactly "1967-01-15". Getting it 90% right isn't good enough when precision matters.
from ragas.metrics.collections import ExactMatch
scorer = ExactMatch()
result = await scorer.ascore(
reference="Paris",
response="India"
)
# Score: 0.0 — not Paris, full stop
Best used for: tool call argument validation, structured data extraction, API response checking.
6. String Presence — is the keyword in there?
The simplest metric of all. Does the response contain the reference string? Yes = 1. No = 0.
Think of it like a keyword checker. You want to make sure the AI always mentions your brand name in its response. Or always includes the word “disclaimer” in legal summaries. String Presence is your tool.
from ragas.metrics.collections import StringPresence
scorer = StringPresence()
result = await scorer.ascore(
reference="Eiffel Tower",
response="The Eiffel Tower is located in India."
)
# Score: 1.0 — "Eiffel Tower" is in there, job done
Best used for: keyword enforcement, required phrase checking, content policy validation.
When to use which one — the quick guide
Your situation Best metric Checking short factual answers (dates, names, codes) Exact Match Checking if a required keyword is present String Presence Comparing fluency of two similar texts String Similarity Evaluating translations or structured short answers BLEU Score Checking if a summary captured the key content ROUGE Score Evaluating multilingual or paraphrased responses CHRF Score
Current limitations — keeping it real
These metrics are fast and free. But they have genuine blind spots you should know about.
They don’t understand the meaning. “The tower is in Paris” and “Paris houses the tower” are semantically identical, but traditional metrics might score them as different because the word order changed.
They punish correct paraphrasing. If your AI gives a correct answer in different words than your reference, traditional metrics will score it lower. That’s a false negative, and it can mislead you.
They can’t catch subtle factual errors. If the reference says “1967” and the response says “1968”, String Similarity scores it very high because the texts are 99% identical at the character level. A human or LLM judge would immediately flag that as wrong.
They don’t handle synonyms. “automobile” and “car” mean the same thing. To BLEU and ROUGE, they’re completely different words.
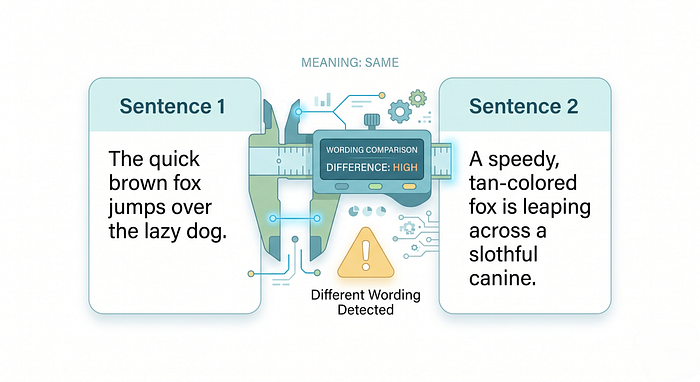
Place: Under “Current limitations”, specifically after the point about punishing correct paraphrasing.
What’s coming next in this space
Hybrid evaluation pipelines are becoming standard. Smart teams are combining traditional metrics (fast, cheap, consistent) with LLM metrics (smart, nuanced) in the same evaluation run. Use traditional metrics as a fast first filter if something scores below 0.5 on ROUGE, flag it for deeper LLM review. Only spend the API budget on borderline cases.
Domain-specific custom metrics are the next frontier. Out-of-the-box metrics only go so far. The most powerful evaluation systems are those built around what your application considers a correct answer. That’s exactly what Part 5 of this series is about.
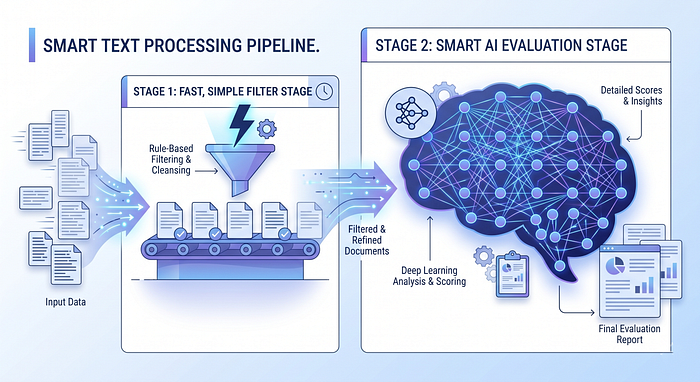
Under “What’s coming next in this space”, illustrating the concept of the hybrid evaluation pipeline.
The bottom line
Remember the translation office from 2003? They needed to evaluate 10,000 documents without breaking the bank or burning out their team. A simple counting formula saved the day, not because it was smarter than a human, but because it was consistent, fast, and good enough for the job at hand.
Your AI app has moments like that, too. Not every answer needs a panel of AI judges. Sometimes you just need to check if the right word is in there, or if the response is 90% the same as expected. For those moments, traditional metrics are your best friend.
Start simple. Scale smart. And always know which tool fits the job.
All code examples and metric definitions are sourced from the official Ragas documentation.
More in artificial-intelligence



Cubed
Write about the technologies shaping the future.
For developers, founders, and curious minds exploring AI, crypto, Web3, and emerging tech—signal over noise.
One free account across In Plain English, Stackademic, Venture, and Cubed.
How it works- AI, crypto & Web3
- Software & emerging technologies
- Analysis & practical resources
- Thoughtful voices, not hype
Sign in
Google or GitHub
Complete profile
Takes a few minutes
Get approved & publish
Start sharing
Why write for Cubed?
The future deserves thoughtful voices, not just louder headlines.
Comments
Loading comments…