
What Is a Large Language Model (LLM)?
At its core, a large language model is a deep learning model that continually predicts the next token based on a prompt and the preceding context. It is trained on massive amounts of text data, repeatedly learning the same basic pattern: look at what comes before, then predict what comes next. With that in mind, let’s first look at the core architecture behind modern LLMs: the decoder-only Transformer.
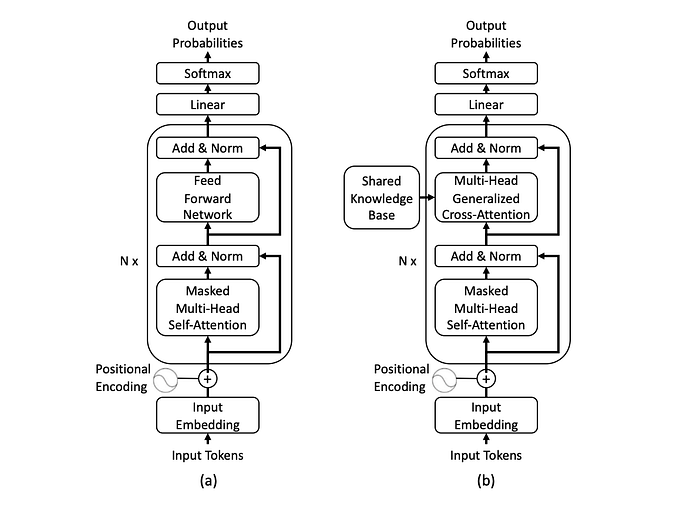
Figure 1. A standard decoder-only Transformer used for next-token prediction.
Reading the diagram from bottom to top, the text is first split into tokens, which are then converted into vectors through the input embedding layer and combined with positional encodings to preserve order information. These representations are then passed through a stack of decoder blocks. In each block, the model first uses masked multi-head self-attention to read the preceding context and identify the most relevant information at the current step, without ever looking ahead to future tokens. It then refines those representations through the feed-forward network, while the add-and-norm operations help keep training stable. Once the information reaches the top of the network, it passes through a linear layer and softmax to produce a probability distribution over the next token.
During pretraining, the model repeats the same process over massive amounts of text: it looks at the preceding tokens, predicts the next one, compares that prediction with the actual next token, and updates the Transformer’s parameters accordingly. In that sense, this diagram illustrates how an LLM is originally trained through next-token prediction, step by step. At inference time, the model uses the same generation mechanism, but its parameters are no longer updated.
After enough large-scale next-token prediction training, the model begins to learn far more than simple word continuation. It gradually picks up language structure, knowledge associations, and reasoning patterns, and may even begin to exhibit something close to human-like intelligence. When model size, data scale, and training compute cross a certain threshold, these capabilities can become much more pronounced. We often refer to this phenomenon as emergence.
But even that is not enough. Although a pretrained model may already possess strong language ability and broad foundational competence, it does not necessarily align with human needs. It may answer the wrong question, fail to follow instructions, behave unreliably, or simply be impractical to use. That is why modern LLMs typically go through a series of alignment and post-training steps to become more useful. Let’s look at how that works.
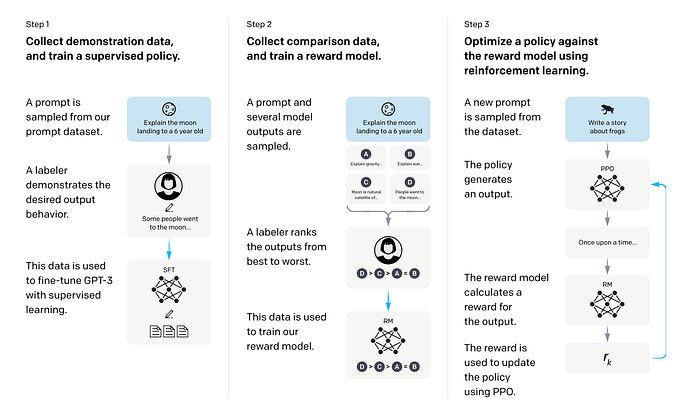
Figure 2. The standard LLM post-training pipeline: SFT, reward modeling, and PPO.
- SFT (Supervised Fine-Tuning): This stage uses human-written demonstration data to teach the model how people expect it to respond. You can think of it as first asking a group of humans to provide example answers, then training the model to imitate them so its replies become more natural, more useful, and more aligned with how a person would actually respond.
- Reward Model (RM): Next, instead of giving the model a single “correct” answer, humans compare multiple responses and decide which one is better. A separate reward model is then trained to act like a grader that learns these human preferences.
- PPO (Proximal Policy Optimization): Finally, the model is continuously adjusted based on the scores given by that grader. In simple terms, this means the model is no longer just copying examples — it is being optimized to produce responses that better match human preferences and are more helpful in practice.
The InstructGPT paper follows exactly this three-step process — SFT, RM, and PPO — to push GPT-3 toward behavior that better matches user intent.
After this layer of post-training, a pretrained large language model starts to look much more like the LLM assistant we are familiar with today: more natural in the way it speaks, and more capable of handling practical tasks.
Even so, in this article we still treat an LLM as the smallest unit of intelligence. To solve complex real-world problems, a single LLM is not enough. And that is exactly why we need to move beyond the model itself and develop LLM systems.
Why Is a Single LLM Not Enough?
Even after post-training and iterative fine-tuning, modern large language models — including the latest GPT-5 series — can generate remarkably high-quality answers when given enough context. Still, they retain important technical limitations that cannot be solved by training the model alone:
- Knowledge is not updated in real time An LLM mainly knows what it saw during training. If the world changes, documents get updated, or internal company knowledge shifts, the model does not automatically know that. Ask it about something that happened today, and without live retrieval, it may simply make things up.
- It can sound right while being wrong This has been one of the biggest risks of LLMs from the start. A model can respond fluently and confidently, yet still be incorrect, fabricated, or unsupported. This is what we usually call hallucination.
- It often cannot show where the answer came from Even when the answer is correct, you may still not know which document, fact, or source it relied on. In many real-world settings, that is a serious problem. A useful answer is not always enough. You also need traceability.
- It lacks persistent memory and state management An LLM is closer to a very strong real-time responder than to a system that can reliably keep track of task progress, user preferences, past decisions, and intermediate state over time. That is one reason later agent systems place so much emphasis on memory.
- It does not naturally use external tools Many real tasks require more than answering in text. They require searching, calling APIs, running code, querying databases, or interacting with external environments. A standalone LLM is still, at its core, a language-generation engine. It is not built to do all of that on its own.
- It struggles with long, multi-step tasks A single question is one thing. A task that requires decomposition, planning, execution, and revision is another. In those settings, an LLM is much more likely to lose track, drift off course, or fail to maintain a long-horizon plan. That is also why LLM agent planning has become an important research area.
- It does not come with built-in verification and feedback Just because an LLM produces an answer does not mean the answer has been checked. In high-stakes settings, the missing piece is often not another generation, but system-level mechanisms such as verifiers, evaluations, and feedback loops that ensure the result is actually trustworthy and usable.
Three Main Ways to Improve an LLM
Now let’s look at the main ways people improve LLM performance. OpenAI presents these common optimization methods as a very practical matrix:
- Moving upward means context optimization, which focuses on giving the model the information it needs.
- Moving to the right means LLM optimization, which focuses on making the model’s behavior more stable and better aligned with the task.
Reading the diagram this way, the most common improvement strategies fall into four positions:

- Prompt engineering This sits in the bottom-left corner and is usually the starting point for any optimization effort. It does not change the model itself or bring in external knowledge. Instead, it improves results through clearer task instructions, output format requirements, role prompting, and few-shot examples. It is the fastest, cheapest, and most common first step.
- RAG Moving upward means adding external context. When the model does not know the latest information, lacks access to private data, or needs traceable evidence, prompt design alone is not enough. You first retrieve relevant external knowledge, then place it into the prompt. That is the core idea behind RAG.
- Fine-tuning Moving to the right means improving the model’s behavior itself. When the problem is not missing knowledge but unstable formatting, inconsistent tone, poor instruction-following, or unreliable task performance, fine-tuning adjusts the model’s weights directly so those behaviors are learned more deeply.
- RAG + Fine-tuning The top-right corner combines both approaches. RAG supplies up-to-date or external knowledge, while fine-tuning improves behavioral consistency and output stability. This is often a more complete solution, but it is also more time-consuming and more complex to implement.
So the goal is not to throw every optimization method at the problem from the start. The real question is whether the gap comes from missing context or unstable behavior. These methods can absolutely be stacked, but using all of them does not automatically lead to the best result. The right strategy depends on the actual failure mode of the system.
The Core Components of an LLM System
A single LLM call is still just a model generating text. It only becomes a real system once we start augmenting it with context, external tools, execution flow, and mechanisms for verification.
This is also where we begin to touch on the idea of an agent. An agent is an autonomous system situated in an environment. It can perceive that environment, take action within it, and move toward a goal. From this perspective, an agent is not something separate from an LLM system. It is better understood as a more advanced implementation of one. Once a system can observe its environment, call tools, execute workflows, and keep adjusting based on feedback, it already begins to take on the core properties of an agent. With that in mind, let’s break down the core components of an LLM system.
Model
The model is the intelligence core of the entire system. It is responsible for understanding, reasoning, and generation. Without the model, there is no LLM system. But the model alone is still not enough.
Context
Context determines what the model sees at any given moment. It includes the prompt, instructions, conversation history, few-shot examples, retrieved documents, and even memory. In many cases, the difference in system performance does not come from the model itself, but from whether the right context is being provided.
Tools
Tools allow the model to do more than just speak. Search, databases, calculators, code execution, and API calls all serve as bridges between the model and the outside world.
Workflow
Workflow determines how the system gets a task done. It decides when to retrieve information, when to call a tool, when to retry, and when to reflect. A single question-and-answer exchange is the simplest workflow. Once the system moves into multi-step, iterative, stateful loops, it starts to move closer to an agent.
Feedback & Evaluation
Evaluation determines whether an AI system can actually be trusted. Verifiers, guardrails, human review, offline evaluation, and online telemetry are not part of the model itself, but they often determine whether a system can be deployed in practice. The feedback layer, in turn, determines whether the system can continue improving as it interacts with its environment.
In simple terms, a complete LLM system is built by combining the model, context, tool use, workflow, evaluation, and feedback in different ways. That is what it means to move from thinking about a model in isolation to designing a system around it.
From LLM to LLM System
A single LLM provides the core capability of language intelligence. But what allows it to handle complex real-world tasks is not the model alone. It is the surrounding system of context, knowledge injection, tool use, workflow control, and feedback and evaluation. Once these pieces are assembled, the LLM stops being just a text-generating model and becomes a system that can actually solve problems.
More in artificial-intelligence



Cubed
Write about the technologies shaping the future.
For developers, founders, and curious minds exploring AI, crypto, Web3, and emerging tech—signal over noise.
One free account across In Plain English, Stackademic, Venture, and Cubed.
How it works- AI, crypto & Web3
- Software & emerging technologies
- Analysis & practical resources
- Thoughtful voices, not hype
Sign in
Google or GitHub
Complete profile
Takes a few minutes
Get approved & publish
Start sharing
Why write for Cubed?
The future deserves thoughtful voices, not just louder headlines.


Comments
Loading comments…