RAG Is Not Just Vector Search: The Retrieval Engineering Behind Reliable LLM Systems
12 min readLucien

Your RAG Is Not Failing Because of the LLM
When a RAG system gives a wrong answer, the first instinct is always the same: the model is too weak, not smart enough — maybe we should just switch to a bigger LLM.
Calm down.
The problem is often not the model. It’s that your evidence supply chain is already broken upstream. Maybe you retrieved the wrong documents, chunked them poorly, or ranked them incorrectly. The result is not that the model can’t answer — it’s that it’s given incomplete, misleading, or noisy evidence, and then confidently produces nonsense.
That’s why RAG is hard. The real challenge is whether you can turn external knowledge into correct, usable, and traceable evidence before handing it to the model.
RAG Is an Evidence Supply Chain
At its core, what makes RAG powerful is not that it adds a search box to an LLM. It’s that it takes all the messy, fragmented, and non-answerable knowledge outside the model, and processes it into evidence that can actually be used during generation.
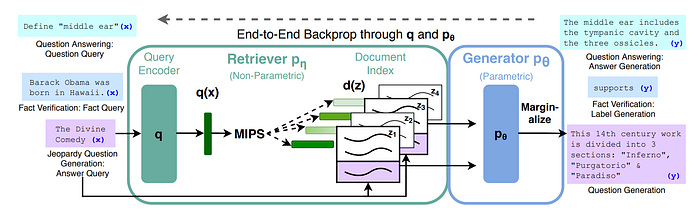
Figure 1. RAG is not merely “search then answer”; it is a system that turns external knowledge into usable evidence for generation.
If you look at the canonical RAG diagram, the query does not go directly into the model to produce an answer. It first goes through retrieval, pulling information from external knowledge sources, and only then is passed to the generator.
So the core of RAG is not whether you “found something,” but whether the retrieved content can be turned into reliable evidence at generation time.
In that sense, RAG is not just search. It is a supply chain that transforms external knowledge into usable evidence.
Why Vector Search Alone Is Not Enough
If the core of RAG is to retrieve external knowledge, then it’s tempting to think the problem is mostly solved once you embed your documents and throw them into a vector database.
But here’s the catch: vector search is actually answering a much narrower question — which chunks are similar to the query in embedding space?
That’s valuable. Dense retrieval is great at handling the term mismatch problem that often breaks keyword search. But it does not guarantee that the retrieved content is the most appropriate evidence for answering the question.
And in many cases, exact matching still matters. For proper nouns, dates, legal clauses, or product identifiers, lexical methods like BM25 often remain critical. Recent retrieval research consistently shows that sparse and dense methods are complementary rather than interchangeable.
This is why hybrid retrieval is so common in practice. Because similarity is only one signal in evidence selection — it is never the full picture of evidence quality.
Chunking: The First Hidden Design Decision in RAG
Let’s move to a more fundamental question:
What exactly does your system treat as a chunk?
Chunking is not just a minor preprocessing step. It is the first hidden design decision in RAG. It determines the unit of information that is eligible to be retrieved, ranked, and cited as evidence.
- If chunks are too small, sentence meaning, coreference, and local context get fragmented. Even if the retriever finds the “right” piece, it may only be a partial or broken piece of evidence.
- If chunks are too large, irrelevant content and redundancy get pulled in together, diluting relevance, hurting ranking quality, and introducing noise — including the well-known lost-in-the-middle problem.
Recent work consistently shows that chunk size has a significant impact on retrieval effectiveness, and there is no one-size-fits-all setting. Short, fact-based queries often benefit from smaller chunks, while questions that require broader context or multi-hop reasoning tend to benefit from larger chunks or more structured segmentation.
In other words, chunking is not just about splitting documents. It is about defining what your RAG system considers to be evidence.
From BM25 to Embeddings: Two Different Notions of Relevance
So how does the system decide what is relevant? To answer that, you need to understand that BM25 and embedding-based retrieval are solving different notions of relevance:
- BM25: does this text explicitly match the terms in the query?
- Embedding retrieval: is this text semantically similar to what the query is asking?
The former excels at exact matching, including keyword overlap, proper nouns, product IDs, legal clauses, and dates, where precision cannot be approximated. The latter is better at handling paraphrases, semantic similarity, and cases where the wording differs but the meaning is the same.
So dense retrieval is not a superior replacement for BM25. It is a different relevance function altogether.
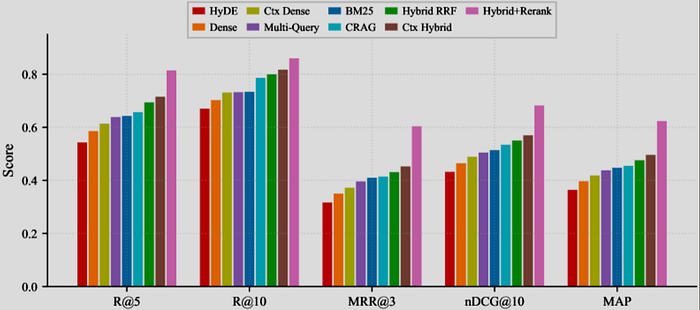
Figure 2. BM25 and dense retrieval capture different notions of relevance, and hybrid retrieval often performs best by combining both lexical and semantic signals.
Research also shows that while dense retrieval is better at handling lexical mismatch, BM25 and other sparse methods can still outperform it on tasks that rely heavily on exact term overlap, proper nouns, or structured signals.
When the two are combined into hybrid retrieval, the results are often more stable and robust. The figure here is a good example. On this benchmark, BM25 clearly outperforms dense retrieval, while the hybrid method performs even better overall.
This again highlights a key point: in real-world systems, relevance is never one-dimensional. Both lexical relevance and semantic relevance matter.
Inside the Vector Database: ANN, HNSW, and FAISS
In a RAG setting, we convert chunks into vectors. But this immediately raises a practical question: if your database contains hundreds of thousands, millions, or even billions of vectors, how can the system compare a query against every single one?
This is what a vector database is actually solving. Its core goal is to make semantic search work at scale.
ANN
ANN stands for Approximate Nearest Neighbor. The key idea is simple: instead of insisting on finding the exact nearest neighbors every time, the system accepts results that are “close enough” in exchange for much faster queries and lower cost.
For large-scale vector search, this is not an optional optimization. It is a requirement.
HNSW
HNSW is a classic ANN method. You can think of it as a hierarchical navigation graph. The upper layers are sparse and help you quickly jump to the right region of the space. As you move down, the connections become denser, allowing more precise local search.
Instead of scanning the entire vector space, the system follows a path that first narrows down the region and then refines the search.
FAISS
FAISS is an open-source vector search library from Meta and is a common foundation behind many vector databases. It is not a single method, but a toolbox of indexing strategies, including brute-force, IVF, PQ, HNSW, and more.
Different data scales, memory budgets, and latency constraints require different indexing choices. FAISS exposes these trade-offs so you can make engineering decisions.
Retrieval Engineering: Query Rewrite, Hybrid Search, and Reranking
In production RAG, retrieval is rarely a single step. It is typically a five-stage pipeline: query rewrite → candidate retrieval → hybrid merge → reranking → evidence selection.
All five steps serve the same goal: to progressively compress an initial pool of “somewhat relevant” data into a small set of evidence that is actually worth sending to the prompt.
Ma et al. summarize the core flow as Rewrite-Retrieve-Read, which is a useful framing. In practice, however, real systems usually add merge and reranking on top, making the evidence pipeline more complete.
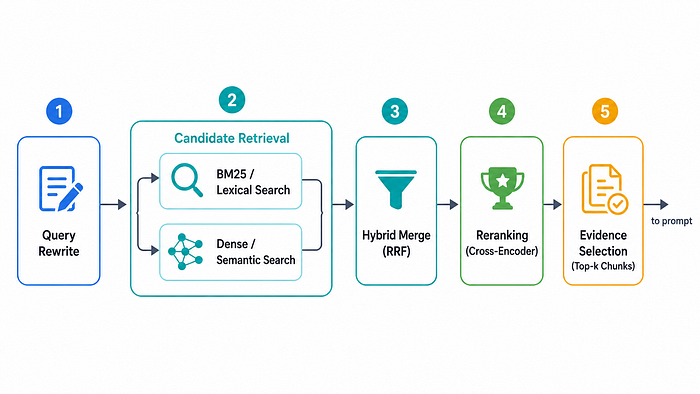
Figure 3. Production RAG retrieval pipeline (query rewrite → retrieval → merge → rerank → select). Made by author.
1. Query rewrite
Many queries do not fail because the information is missing, but because the wording is not suitable for retrieval. Users tend to use conversational language, abbreviations, or references, while knowledge bases are written in document, product, or legal language.
Rewriting the query into a more retrieval-friendly form often helps bridge this gap.
2. Candidate retrieval
In practice, systems rarely rely on a single retriever. BM25 and other lexical methods are strong at capturing signals that require exact matching, such as proper nouns, version numbers, product IDs, and dates. Dense retrieval is better at handling semantic mismatch, where the wording differs but the meaning is similar.
The candidates returned by these methods are often different, which is exactly why they are complementary.
3. Hybrid merge
After retrieval, systems usually do not pick one method over the other. Instead, they combine the results. One of the most common and intuitive approaches is RRF.
Rather than directly comparing scores across retrievers, RRF looks at which documents consistently rank well across multiple lists and rewards that agreement.
4. Reranking
The earlier steps focus on gathering a broad set of potentially relevant candidates. Reranking is where precision begins.
A reranker re-evaluates the alignment between the query and each candidate at a finer level, compressing the pool of “possibly relevant” results into a much smaller set of evidence that is actually worth sending to the prompt.
5. Evidence selection
At this stage, only a small number of chunks are passed into the prompt.
This is where the nature of retrieval engineering becomes clear. The goal is not simply to retrieve data, but to progressively compress a large set of candidates into a small set of evidence that can meaningfully influence the final answer.
Context Orchestration: Retrieval Is Only Half the Battle
Retrieving the right evidence only gets you halfway there. What really determines the quality of the answer is how that evidence is presented to the LLM.
A common mistake is to assume that more context is always better. In reality, once top-k gets too large, attention becomes diluted, while cost and noise both increase. Even if the retrieved content is correct, passage ordering still matters, because models do not treat all positions equally. When important information is placed in the wrong position, performance can drop significantly.
This is why, after retrieval, systems often need an additional step to refine the evidence. In practice, this usually means keeping key sentences and removing redundant content, making the context shorter and cleaner. When necessary, citation tags and evidence labels can also be added to help the model understand where each piece of information comes from and which claim it supports.
When there is a large amount of evidence, it can also be fed to the model in batches or segments, rather than all at once, to avoid everything competing for attention in a single prompt.
At the end of the day, many RAG failures are not caused by poor retrieval, but by coarse evidence presentation.
The Lost-in-the-Middle Problem
Let’s address a very common question:
Why does the model still fail, even when I’ve already put the correct information into the prompt?
In many cases, the issue is not what goes in, but how it goes in. When the context is too long, too noisy, or poorly ordered, important information can easily get buried in the middle. The model may “see” both the beginning and the end, but fail to effectively use the key evidence that actually matters.
This is what makes the lost-in-the-middle problem so frustrating. It reminds us that simply putting the right evidence into the prompt does not guarantee that the model will use it properly. As a result, the solution is not just to increase the context window. It requires going back to orchestration, and rethinking how top-k is set, how passages are ordered, how content is compressed, and how evidence is provided in stages.
In short, the goal is to make sure that the right information is not only present, but actually used by the model.
How to Evaluate RAG Beyond “Looks Good”
Evaluating RAG based solely on how fluent the final answer sounds is not enough. A response can appear convincing while still being grounded in incorrect evidence.
A better approach is to break evaluation down into a few fundamental dimensions:
- Retrieval quality: whether the correct documents are retrieved, commonly measured with Recall@k, MRR, and nDCG
- Groundedness: whether the answer is actually supported by the retrieved evidence, often measured with faithfulness or groundedness
- Citation attribution: whether citations correctly point to the passages that support each claim, avoiding phantom citations
- End-to-end task success: whether the overall task is successfully completed, measured by metrics such as exact match, F1, or human evaluation
I’ll cover how to properly evaluate RAG in a separate article.
RAG, Fine-Tuning, and Database Adapters Are Not the Same Tool
RAG, fine-tuning, and database adapters are often discussed together, but they actually solve three different types of problems:
- RAG deals with external evidence. It allows the model to retrieve the right information at the time of answering.
- Fine-tuning deals with model behavior. It helps the model follow a specific format, style, or task pattern more consistently.
- Database adapters handle precise queries. They translate natural language into reliable access to structured data systems.
In short, RAG adds knowledge, fine-tuning shapes behavior, and database adapters enable precise data access.
So in a mature system, it is rarely about choosing one over the others. The key is to understand which type of problem you are solving, and assign it to the right tool.
Beyond Naive RAG: Agentic RAG, Self-RAG, GraphRAG, and LongRAG
Recent developments in RAG have taken many different directions, but at their core, they are all addressing the limitations of naive RAG.
- Agentic RAG focuses on when to retrieve, how to retrieve, and whether to retrieve again.
- Self-RAG focuses on whether the model can evaluate and refine its own retrieval and revision.
- GraphRAG shifts from chunks to structured knowledge, such as entities and relations.
- LongRAG rethinks how chunks and evidence should be organized under long-context settings.
These may look like four different directions, but they share the same underlying goal: to make external knowledge more reliably usable as evidence.
Takeaway
- RAG is not about retrieving data, but about turning external knowledge into usable and trustworthy evidence.
- System quality depends on the entire pipeline, not just the model.
- Think in terms of evidence engineering, not “search then answer.”
More in artificial-intelligence



Cubed
Write about the technologies shaping the future.
For developers, founders, and curious minds exploring AI, crypto, Web3, and emerging tech—signal over noise.
One free account across In Plain English, Stackademic, Venture, and Cubed.
How it works- AI, crypto & Web3
- Software & emerging technologies
- Analysis & practical resources
- Thoughtful voices, not hype
Sign in
Google or GitHub
Complete profile
Takes a few minutes
Get approved & publish
Start sharing
Why write for Cubed?
The future deserves thoughtful voices, not just louder headlines.


Comments
Loading comments…