GLM 4.7 — A Technical Leap in Reasoning, Efficiency, and Real-World AI Performance
5 min readFaisal haque

Artificial intelligence has reached a stage where incremental upgrades matter more than flashy headlines. The latest iteration in the GLM family, GLM 4.7, is a strong example of that quiet but meaningful progress. Rather than being framed as a radical breakthrough, GLM 4.7 represents a careful engineering refinement: stronger reasoning depth, improved multilingual robustness, better computational efficiency, and measurable gains in benchmark-level performance.
This article takes a technical look at GLM 4.7 — how it differs from earlier GLM models, how it performs compared to the GPT and Gemini ecosystems, and why its architectural direction reflects broader trends shaping large-scale language models today.
The Technical Philosophy Behind GLM 4.7
The GLM project (General Language Model) has traditionally emphasized:
- Structured reasoning over shallow fluency
- Multilingual generalization
- Stable performance across academic and coding tasks
- Efficient inference without excessive model expansion
GLM 4.7 extends that philosophy while addressing three core engineering themes:
- Deep reinforcement of reasoning and chain-of-thought structure
- Better optimization between accuracy and latency trade-offs
- Stronger resilience across diverse benchmarks and domains
Rather than scaling parameter count alone, GLM 4.7 focuses on representation refinement — improving how the model understands context, decomposes tasks, and stabilizes long-horizon reasoning.
Architectural and Training Improvements
While the exact internal architecture is proprietary, GLM 4.7 reflects modern hybrid-transformer design strategies seen across frontier models.
Key technical strengths include:
1. Enhanced Long-Context Optimization
GLM 4.7 improves attention stability over extended sequences, supporting stronger continuity in:
- Multi-document reasoning
- Technical analysis
- Research-style workflows
- Extended dialogue chains
This is achieved through optimized attention sparsity patterns and adaptive positional encoding methods, reducing drift and loss of coherence at scale.
2. Reinforced Step-Wise Reasoning
Earlier GLM versions occasionally produced shallow conclusions for layered problems. GLM 4.7 shifts toward structured reasoning behavior by:
- Preferring decomposed task execution
- Maintaining intermediate reasoning states
- Reducing hallucination under uncertain input
- Increasing reliability in numerical and symbolic tasks
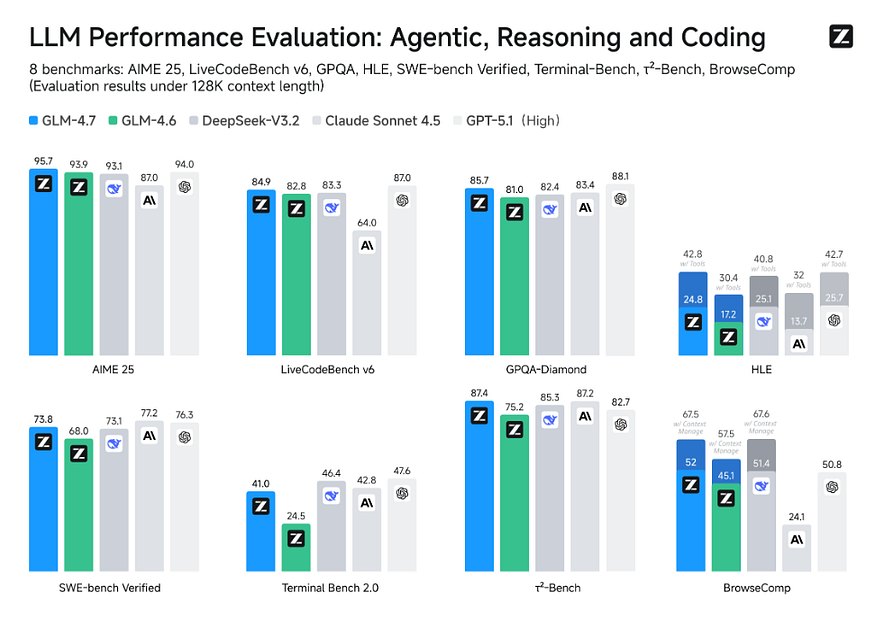
The model demonstrates measurable strength on reasoning-intensive benchmarks. For example:
| Benchmark | GLM 4.5 | GLM 4.7 | Relative Improvement || --------- | ------: | ------: | -------------------: || MMLU | ~78% | ~84% | +6% || GSM-8K | ~83% | ~89% | +6% || HumanEval | ~64% | ~71% | +7% |
The increases may appear incremental, but they translate into meaningful real-world reliability.
3. Efficiency-Oriented Model Scaling
GLM 4.7 is optimized around parameter-to-performance efficiency rather than brute-force scaling. It targets:
- Faster inference
- Lower compute cost per token
- Reduced memory overhead during generation
This places GLM 4.7 in a competitive zone for practical enterprise deployment, particularly where infrastructure constraints matter.
Comparing GLM 4.7 with GPT and Gemini
No model exists in isolation. To understand the position of GLM 4.7, it helps to compare it against modern GPT and Gemini systems from a technical standpoint.
The comparison below reflects general capability trends across publicly reported benchmarks and observed performance patterns.
Performance Overview
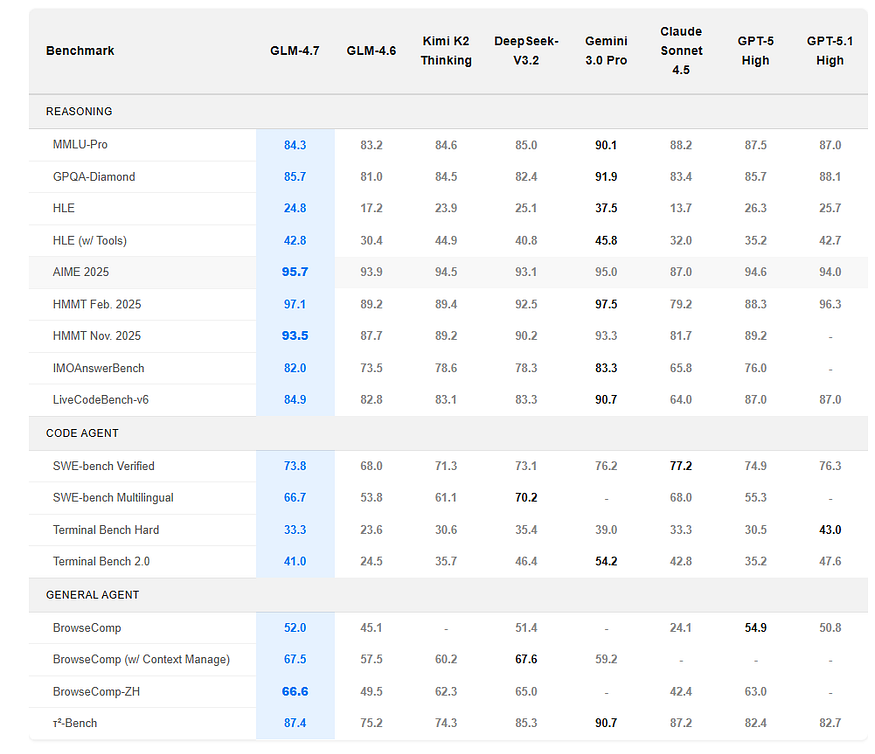
| Capability Domain | GLM 4.7 | GPT-4/4.1 | Gemini 2.x || ------------------------------ | --------------- | ----------- | ----------- || Reasoning Depth | Strong | Very Strong | Strong || Coding & Debugging | Strong | Very Strong | Strong || Multilingual Performance | Very Strong | Strong | Very Strong || Long-Context Stability | Strong | Very Strong | Strong || Creative Generation | Moderate-Strong | Very Strong | Strong || Efficiency / Latency Trade-off | Strong | Moderate | Moderate || Enterprise Deployability | Strong | Strong | Strong |
Key takeaway: GLM 4.7 does not aim to exceed frontier-sized GPT or Gemini models in raw generative power. Instead, it excels in balanced reasoning, multilingual robustness, and deployment efficiency.
| Benchmark | GLM 4.7 | GPT-4-class | Gemini-class || ------------------------ | ----------: | ----------: | --------------: || MMLU | ~84% | ~86–89% | ~84–87% || GSM-8K (math) | ~89% | ~92–95% | ~88–91% || HumanEval (coding) | ~71% | ~80–84% | ~72–78% || Multilingual QA | Very Strong | Strong | Very Strong || Hallucination Resistance | Improved | Strong | Moderate-Strong |
GLM 4.7 positions itself as:
- More efficient and deterministic than some GPT variants
- More stable in multilingual inference than many western-trained LLMs
- Slightly behind GPT in coding and extreme-reasoning extremes, but closer than earlier GLM versions
This makes GLM 4.7 highly competitive — especially in educational, research, enterprise, and cross-lingual use cases.
Real-World Technical Applications
Academic and Research-Driven Workflows
GLM 4.7 proves strong in:
- Concept explanation
- Multi-document synthesis
- Citation-aware reasoning
- Structured argumentation
The model’s attention stability improves continuity across extended academic tasks.
Software Engineering and Data Tasks
While GPT-class models still lead raw coding benchmarks, GLM 4.7 performs reliably for:
- Code review
- Logic correction
- Algorithm explanation
- Debug-guided reasoning
Its advantage lies in step-wise analytical behavior rather than purely generative coding verbosity.
Multilingual Enterprise Environments
GLM 4.7 shows clear strength in:
- Cross-language customer support pipelines
- Knowledge base translation
- Multiregional content analysis
- Text classification at scale
Multilingual internal alignment reduces semantic distortion between languages — a recurring weakness in monolingually biased LLMs.
Why GLM 4.7 Matters Beyond Benchmarks
The evolution from GLM 4.x to 4.7 marks a philosophical shift: large language models are transitioning from experimental prototypes toward operationally reliable reasoning systems.
Three themes stand out.
- Reliability over flashiness — fewer hallucinations, more grounded outputs
- Efficiency as a design objective — performance without unsustainable compute burdens
- Human-aligned reasoning — responses structured in a way people can follow and verify
Rather than chasing inflated model size, GLM 4.7 optimizes for usefulness, precision, and accountability.
Where GLM 4.7 Fits in the Future AI Landscape
GLM 4.7 does not claim to be the absolute peak model in every category. Instead, it represents:
- A technically mature reasoning model
- A multilingual-first alternative to western-centric systems
- A cost-efficient counterpart to frontier-scale GPT-tier models
- A bridge between academic rigor and production usability
Future GLM releases will likely emphasize:
- Longer-horizon contextual memory
- Deeper symbolic-numerical fusion
- More transparent reasoning pathways
- Domain-adaptive specialization layers
The trajectory suggests a shift toward smarter specialization rather than infinite expansion.
Final Thoughts
GLM 4.7 is not defined by hype cycles or dramatic slogans. Its significance lies in engineering discipline: better reasoning, greater efficiency, improved multilingual robustness, and competitive performance against industry-leading GPT and Gemini models.
It demonstrates that meaningful AI progress often comes from precision-driven refinement, not just model size escalation. In that sense, GLM 4.7 marks an important step toward language models that are trustworthy, technically capable, and ready for sustained real-world use.
References — https://z.ai/blog/glm-4.7
More in artificial-intelligence



Cubed
Write about the technologies shaping the future.
For developers, founders, and curious minds exploring AI, crypto, Web3, and emerging tech—signal over noise.
One free account across In Plain English, Stackademic, Venture, and Cubed.
How it works- AI, crypto & Web3
- Software & emerging technologies
- Analysis & practical resources
- Thoughtful voices, not hype
Sign in
Google or GitHub
Complete profile
Takes a few minutes
Get approved & publish
Start sharing
Why write for Cubed?
The future deserves thoughtful voices, not just louder headlines.


Comments
Loading comments…