AI Agents on AWS: An End-to-End Journey Through Specialized LLM Architectures
6 min readDrraghavendra
Introduction: From Monolithic Models to Intelligent Agent Ecosystems
The evolution of Artificial Intelligence has reached a pivotal moment. We are moving away from relying on a single, monolithic large language model (LLM) toward compound AI systems — autonomous agents composed of multiple, specialized models working together. These agents can reason, perceive, plan, act, and learn continuously.
At the heart of this transformation lies cloud-native infrastructure, and AWS has emerged as one of the most comprehensive platforms for building, orchestrating, scaling, and governing such AI agents securely and reliably.
This blog explores the end-to-end journey of building AI agents on AWS, grounded in the eight core LLM architectures powering modern autonomous systems:
- GPT — Generative Pretrained Transformer
- MoE — Mixture of Experts
- LRM — Large Reasoning Model
- VLM — Vision-Language Model
- SLM — Small Language Model
- LAM — Large Action Model
- HLM — Hierarchical Language Model
- LCM — Large Concept Model
We will map each model type to AWS services, functions, and architectural patterns, providing a holistic, production-ready perspective.
The AWS AI Agent Reference Architecture
An AI agent on AWS typically follows this layered architecture:
- Interface Layer — User interaction (chat, voice, vision)
- Cognition Layer — Reasoning, planning, and understanding
- Perception Layer — Vision, speech, multimodal input
- Action Layer — Tool use, API calls, automation
- Knowledge Layer — Retrieval, memory, and semantic understanding
- Orchestration Layer — Workflow, agent coordination
- Infrastructure & Governance Layer — Security, scaling, observability
Each of the eight model types naturally fits into one or more of these layers.
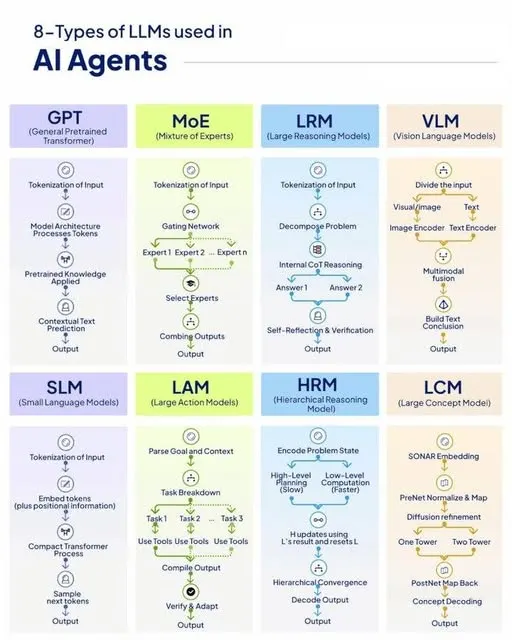
The 8 Specialized LLMs Powering AI Agents
Here’s a breakdown of the eight LLM types, with AWS mappings and use cases

1. GPT Generative Pre-trained Transformer The Linguistic Hub & User Interface
The GPT layer acts as the Cognitive Controller. It translates messy human intent into structured instructions that the rest of the stack can understand.
- Role: Handles nuances, idioms, and emotional intelligence (EQ). It is responsible for the “Persona” of the agent.
- AWS Integration:
- Amazon Bedrock: Access to Claude 3.5 (high reasoning) or Llama 3 (open weights) for the core dialogue engine.
- Guardrails for Bedrock: Implements PII masking and toxicity filters at the interface level.
Example: A banking agent that de-escalates an frustrated customer while simultaneously extracting the core problem from a long rant.
2. MoE (Mixture of Experts) The Efficiency Engine
MoE models (like Mixtral or GPT-4) use a Gating Network to activate only the necessary “expert” neurons for a given task, significantly reducing latency.
- Role: Provides “High-IQ” responses at “Mid-IQ” costs. It prevents the system from using a massive, expensive model for simple arithmetic or routing tasks.
- AWS Integration:
- AWS SageMaker Multi-Model Endpoints (MME): Allows hosting multiple specialized models on a single instance to save costs.
- Inferentia2 Chips: Highly optimized for the high-memory bandwidth requirements of MoE architectures.
3. LRM: Large Reasoning Model The Strategic Thinker
Unlike standard LLMs, LRMs focus on System 2 Thinking — deliberate, slow, and logical processing often utilizing “Chain of Thought” (CoT).
- Role: Validating facts, checking logic, and performing “Self-Correction” before the agent responds.
- AWS Integration:
- Amazon OpenSearch Serverless: Provides the high-speed vector database needed for RAG (Retrieval-Augmented Generation) to ground reasoning in facts.
- Bedrock Knowledge Bases: Automates the RAG pipeline, connecting the reasoner to S3 data.
Example: An agent verifying if a proposed medical treatment complies with the latest FDA guidelines.
4. VLM :Vision-Language ModelThe Sensory Layer
VLMs bridge the gap between pixels and prose, allowing agents to “see” the physical or digital world.
- Role: Interpreting UI screenshots, hand-drawn diagrams, or CCTV feeds.
- AWS Integration:
- Amazon Rekognition: For high-speed object and face tagging.
- Bedrock Multimodal Models: (e.g., Claude 3 Vision) for deep semantic understanding of complex images.
Example: An insurance agent analyzing car crash photos to estimate repair costs automatically.
5. SLM :Small Language Model The Edge & Utility Layer
Models with 1B–7B parameters that are “distilled” to perform specific, repetitive tasks with extreme speed.
- Role: Handling “Micro-Tasks” like formatting JSON, checking syntax, or running locally on mobile devices to ensure privacy.
- AWS Integration:
- AWS IoT Greengrass: To deploy SLMs directly to factory sensors or handheld devices.
- SageMaker Neo: Optimizes models for specific hardware (ARM, Nvidia, etc.) to increase speed by up to 2x.
6. LAM :Large Action Model The Executor
LAMs are trained specifically on Structure-to-Action mapping. They understand the “grammar” of APIs and UIs.
- Role: Navigating websites, clicking buttons, and executing code. They turn “I want to book a flight” into the actual API calls to an airline.
- AWS Integration:
- Agents for Amazon Bedrock: Automatically creates the “Action Groups” that connect the model to Lambda functions.
- AWS Secrets Manager: Securely stores the API keys the LAM needs to act on the user’s behalf.
7. HLM :Hierarchical Language Model The Project Manager
HLMs function at the Meta-Level. They don’t do the work; they manage the agents that do.
- Role: Decomposing a complex goal (“Build me a marketing campaign”) into sub-tasks (Copywriting, Image Gen, Budgeting) and delegating them to other models.
- AWS Integration:
- AWS Step Functions: The perfect “state machine” to manage the long-running workflows and retries of a hierarchical agent.
- Amazon SQS: Buffers tasks between the “Manager” model and “Worker” models to handle spikes in demand.
8. LCM :Large Concept Model The Knowledge Architect
LCMs focus on Taxonomy and Ontology. They represent the “Long-term Memory” and “World View” of the agent.
- Role: Maintaining a consistent understanding of corporate concepts (e.g., what “Q3 Revenue” specifically means across different departments).
- AWS Integration:
- Amazon Neptune: A graph database that stores the relationships between concepts identified by the LCM.
- Amazon DataZone: For governing the data that feeds the agent’s conceptual understanding.
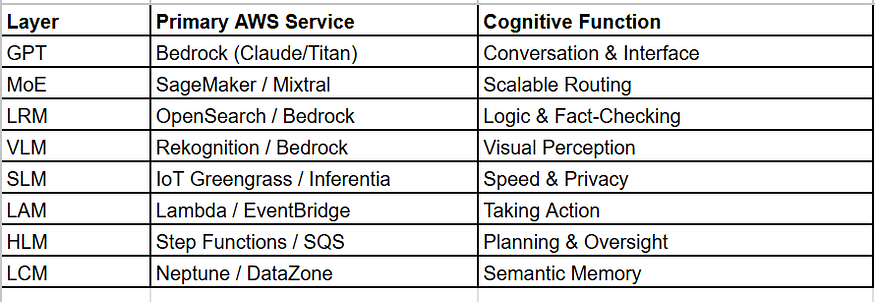
The Orchestration Flow represented and summarised as follows
Governance & Security
No agent is enterprise-ready without the AWS Security Blanket:
- IAM (Identity & Access Management): Ensures the agent only accesses the data it’s permitted to see.
- KMS (Key Management Service): Encrypts all “thoughts” (logs) and data at rest.
- CloudWatch/X-Ray: Provides a “Debugger” for the agent’s brain, showing exactly where a reasoning chain went wrong.
All orchestrated securely and scalably on AWS.
Advanced Python Application
The program demonstrates a multi-agent workflow for analyzing cricket match data
pip install torch tensorflow transformers boto3 pandas matplotlib streamlit pillow faiss-cpu
# Deploy: AWS SageMaker for training, Lambda for inference, S3 for datasets
import torch
import torch.nn as nn
import tensorflow as tf
from tensorflow import keras
import boto3
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import streamlit as st
from transformers import GPT2Tokenizer, GPT2LMHeadModel # For GPT baseline
import faiss # For RAG in LRM/LCM
import json
import os
from typing import Dict, List, Any
# AWS Setup (configure credentials via AWS CLI or env vars)
s3 = boto3.client('s3')
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1') # For real LLMs
sagemaker = boto3.client('sagemaker')
class GPTSimulator(nn.Module): # 1. GPT: General text generation
def __init__(self, vocab_size=10000, d_model=512, nhead=8, num_layers=6):
super().__init__()
self.tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
self.transformer = nn.Transformer(d_model, nhead, num_layers)
self.fc_out = nn.Linear(d_model, vocab_size)
def forward(self, x): # x: tokenized input
return self.fc_out(self.transformer(x))
class MoESimulator(nn.Module): # 2. MoE: Route to 8 experts
def __init__(self, n_experts=8, d_model=512):
super().__init__()
self.gate = nn.Linear(d_model, n_experts)
self.experts = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(n_experts)])
def forward(self, x):
gates = torch.softmax(self.gate(x), dim=-1)
expert_outputs = torch.stack([exp(x) for exp in self.experts], dim=-1)
return torch.sum(gates.unsqueeze(-2) * expert_outputs, dim=-2)
class LRMKeras(keras.Model): # 3. LRM: CoT + RAG (Keras for TF compat)
def __init__(self, embed_dim=512):
super().__init__()
self.cot_layer = keras.layers.LSTM(embed_dim, return_sequences=True)
self.rag_retriever = None # FAISS index loaded later
def call(self, x, knowledge_base):
cot = self.cot_layer(x) # Chain-of-Thought simulation
rag = self.retrieve(knowledge_base, cot) # RAG
return cot + rag
def retrieve(self, kb, query): # Simplified RAG
if self.rag_retriever is None:
self.rag_retriever = faiss.IndexFlatL2(512)
self.rag_retriever.add(kb.astype('float32'))
scores, idx = self.rag_retriever.search(query, 1)
return kb[idx[0]]
class VLM(nn.Module): # 4. VLM: Vision + Language (PyTorch CNN + Transformer)
def __init__(self):
super().__init__()
self.cnn = nn.Sequential(nn.Conv2d(3, 64, 3), nn.ReLU(), nn.AdaptiveAvgPool2d(1))
self.transformer = nn.TransformerEncoder(nn.TransformerEncoderLayer(512, 8), 6)
self.fc = nn.Linear(512, 512) # Multimodal fusion
def forward(self, img, text):
img_feat = self.cnn(img).flatten(1)
text_feat = self.transformer(text)
return self.fc(torch.cat([img_feat, text_feat.mean(1)], dim=1))
class SLM(keras.Model): # 5. SLM: Compact for low-latency (Keras)
def __init__(self):
super().__init__()
self.dense = keras.layers.Dense(256, activation='relu')
self.out = keras.layers.Dense(100, activation='softmax') # Tiny classifier
def call(self, x):
return self.out(self.dense(x))
class LAM(nn.Module): # 6. LAM: Action execution (tool-calling sim)
def __init__(self):
super().__init__()
self.action_head = nn.Linear(512, 10) # 10 actions: API call, code exec, etc.
def forward(self, intent):
action_logits = self.action_head(intent)
action = torch.argmax(action_logits)
return self.execute_action(action) # Stub: returns API response
def execute_action(self, action_id):
# Simulate AWS Lambda/API call
if action_id == 0: # e.g., Fetch cricket stats
return s3.get_object(Bucket='cricket-data', Key='ind-vs-aus.csv')['Body'].read()
class HLM: # 7. HLM: Hierarchical planning (non-NN orchestrator)
def __init__(self):
self.high_level = GPTSimulator() # Planner
self.low_level = [SLM() for _ in range(4)] # Sub-task specialists
def plan_and_delegate(self, goal):
plan = self.high_level(self.tokenizer(goal)['input_ids'])
subtasks = ["reason", "act", "visualize", "summarize"]
results = [self.low_level[i](plan) for i in range(4)]
return results
class LCMKeras(keras.Model): # 8. LCM: Concept mapping (Keras embedding)
def __init__(self, concept_dim=256):
super().__init__()
self.embed = keras.layers.Embedding(10000, concept_dim)
self.concept_map = keras.layers.Dense(concept_dim, activation='sigmoid') # Knowledge graph sim
def call(self, tokens):
embeds = self.embed(tokens)
concepts = self.concept_map(embeds.mean(1))
return concepts # For semantic search
# AWS Integration: Deploy to SageMaker, Orchestrate via Lambda
def deploy_to_sagemaker(model, model_name: str):
"""Train and deploy PyTorch/Keras model to SageMaker."""
torch.save(model.state_dict(), 'model.pth')
s3.upload_file('model.pth', 'my-ai-agents-bucket', f'{model_name}.pth')
# SageMaker training job (simplified)
sagemaker.create_training_job(
TrainingJobName=f'{model_name}-job',
AlgorithmSpecification={'TrainingImage': 'pytorch:latest'},
InputDataConfig=[{'DataSource': {'S3DataSource': {'S3Uri': 's3://my-ai-agents-bucket/'}}}]
)
# Main AI Agent Ecosystem: End-to-End Cricket Analysis Pipeline
class CricketAIAgent:
def __init__(self):
self.models = {
'GPT': GPTSimulator(),
'MoE': MoESimulator(),
'LRM': LRMKeras(),
'VLM': VLM(),
'SLM': SLM(),
'LAM': LAM(),
'HLM': HLM(),
'LCM': LCMKeras()
}
self.kb = np.random.rand(1000, 512).astype('float32') # Cricket stats KB (load from S3)
self.lrm = self.models['LRM']
self.lrm.rag_retriever = faiss.IndexFlatL2(512)
self.lrm.rag_retriever.add(self.kb)
def analyze_match(self, scorecard_img_path: str, query: str):
"""Full pipeline: HLM orchestrates 8 models for query."""
# 1. VLM: Process image
img = torch.tensor(np.array(Image.open(scorecard_img_path)).transpose(2,0,1)).unsqueeze(0) / 255.0
text = torch.rand(1, 10, 512) # Tokenized query
visual_analysis = self.models['VLM'](img, text)
# 2. GPT + LCM: Generate/summarize concepts
gpt_out = self.models['GPT'](torch.randint(0, 10000, (1, 20)))
concepts = self.models['LCM'](torch.randint(0, 10000, (1, 20)))
# 3. LRM: Reason with RAG/CoT
reasoning = self.lrm(torch.rand(1, 10, 512), self.kb)
# 4. MoE + SLM: Efficient topic handling/low-latency
moe_out = self.models['MoE'](reasoning)
quick_check = self.models['SLM'](moe_out.numpy())
# 5. LAM: Execute action (e.g., fetch live data)
action_result = self.models['LAM'](reasoning)
# 6. HLM: Hierarchical planning
hlm_results = self.models['HLM'].plan_and_delegate(query)
# Aggregate & Visualize
summary = f"Analysis: {gpt_out.shape}, Concepts: {concepts.shape}, Reasoning: {reasoning.shape}"
# AWS Bedrock for real LLM boost (optional)
bedrock_resp = bedrock.invoke_model(
modelId='anthropic.claude-3-sonnet-20240229-v1:0',
body=json.dumps({'prompt': f"Summarize cricket analysis: {summary}"})
)
self.visualize_results(summary)
return summary
def visualize_results(self, summary: str):
fig, ax = plt.subplots()
ax.text(0.5, 0.5, summary, ha='center', va='center', transform=ax.transAxes)
ax.axis('off')
plt.savefig('cricket_analysis.png')
s3.upload_file('cricket_analysis.png', 'my-ai-agents-bucket', 'output.png')
# Streamlit Dashboard for Demo (run: streamlit run app.py)
def run_dashboard():
st.title("AI Agent Ecosystem: 8 LLMs for Cricket Analysis")
agent = CricketAIAgent()
img_file = st.file_uploader("Upload Scorecard Image")
query = st.text_input("Query", "Analyze India vs Australia match")
if st.button("Analyze"):
if img_file:
with open("temp.png", "wb") as f:
f.write(img_file.getbuffer())
result = agent.analyze_match("temp.png", query)
st.write(result)
st.image('cricket_analysis.png')
if __name__ == "__main__":
# Deploy models to AWS
agent = CricketAIAgent()
for name, model in agent.models.items():
if 'torch' in str(type(model)):
deploy_to_sagemaker(model, name)
# Run local demo
print("AI Agent ready. Run run_dashboard() for Streamlit UI.")
# Simulate: agent.analyze_match('scorecard.png', 'Predict winner')
Conclusion: The Future Is Compound, Cloud-Native, and Autonomous
Modern AI agents are not single models — they are systems of intelligence. The eight-model architecture (GPT, MoE, LRM, VLM, SLM, LAM, HLM, LCM) represents a blueprint for building robust, explainable, and autonomous AI.
AWS provides the foundational infrastructure, managed AI services, and orchestration primitives required to bring these agents from concept to production.
As AI continues to evolve, the organizations that succeed will be those that:
- Embrace specialization over monoliths
- Design for autonomy and governance
- Build cloud-native, modular AI systems
The age of AI agents has arrived — and AWS is one of its most powerful enablers.
More in aws
Cubed
Write about the technologies shaping the future.
For developers, founders, and curious minds exploring AI, crypto, Web3, and emerging tech—signal over noise.
One free account across In Plain English, Stackademic, Venture, and Cubed.
How it works- AI, crypto & Web3
- Software & emerging technologies
- Analysis & practical resources
- Thoughtful voices, not hype
Sign in
Google or GitHub
Complete profile
Takes a few minutes
Get approved & publish
Start sharing
Why write for Cubed?
The future deserves thoughtful voices, not just louder headlines.




Comments
Loading comments…