Running open AI models for free in under 10 minutes with a Google Colab and no extra accounts? Yes, Please!
8 min read

This article delves into leveraging Colab’s free tier to deploy and run a multimodal LLM AI model in the cloud at no cost and explains the process of making the model’s API accessible for experimentation and development on the web using Localtunnel.
I came across several tutorials on deploying LLM models in the cloud using Colab’s free tier, with many recommending the use of services like Grok to expose APIs to the internet. Grok is a great service, but it requires creating an account, additional Python code for tunneling, and management of API keys — so there’s gotta be a “better” way, right?

And guess what? There is! With just 5 system command lines in Google Colab, I’ll guide you through running Ollama, retrieving the LLaVA 13B multimodal model, and making it accessible online via Localtunnel.
Plus, I’ll walk you through how to engage with the model through a Python script by leveraging the Ollama Python API.
Getting started. Launching a Free Tier Colab Notebook with GPU (Experienced Colab’s Users can skip this step)
This guide requires a Google account for accessing and running notebooks in Colaboratory (Colab). If you’re already familiar with Colab and know how to create an instance with T4 GPU, you can skip this step.
Start by signing in, or if you don’t have a Google account, by creating one here:
https://colab.research.google.com/
After signing in, initiate a new notebook by clicking the “+New Notebook” button.
An empty notebook will appear, which you can rename using the top bar.
To boost our model’s performance, we’ll use Colab’s free GPU tier. This requires navigating to the runtime configuration, selecting T4 GPU as the runtime type, saving the settings, and then pressing the Connect button to activate our environment. The process is illustrated in the gif below:
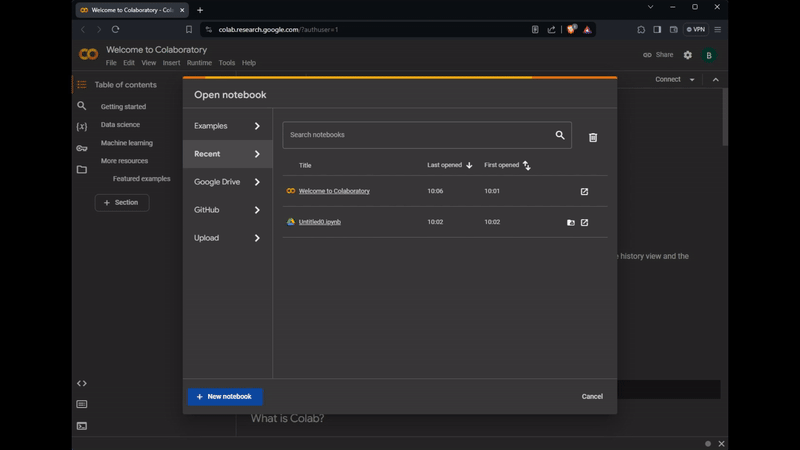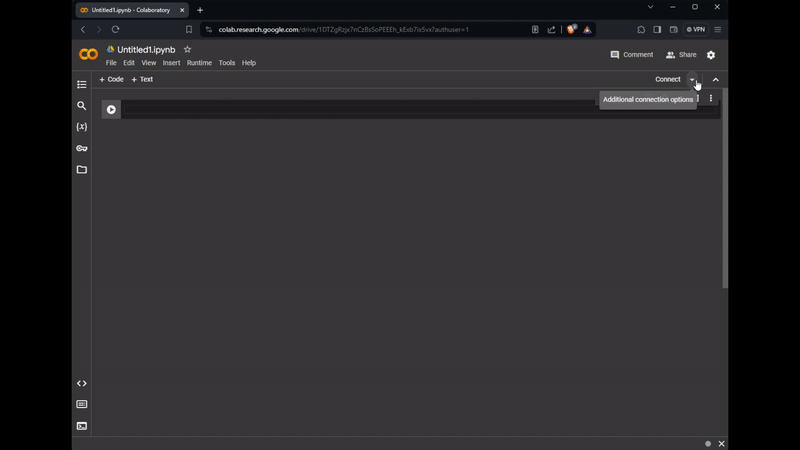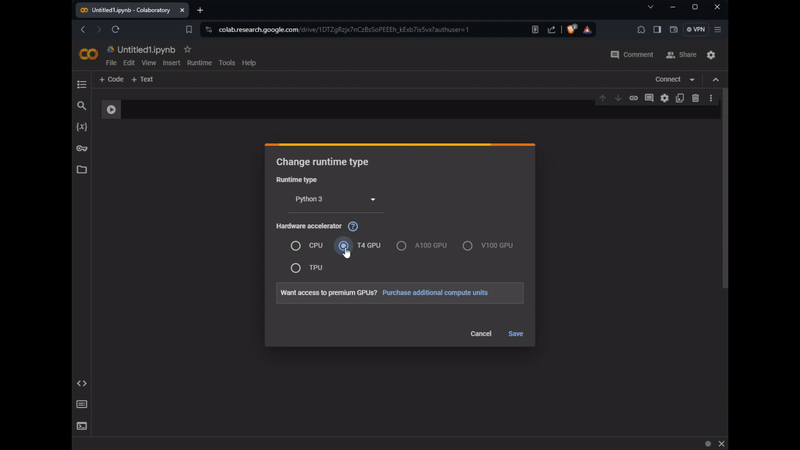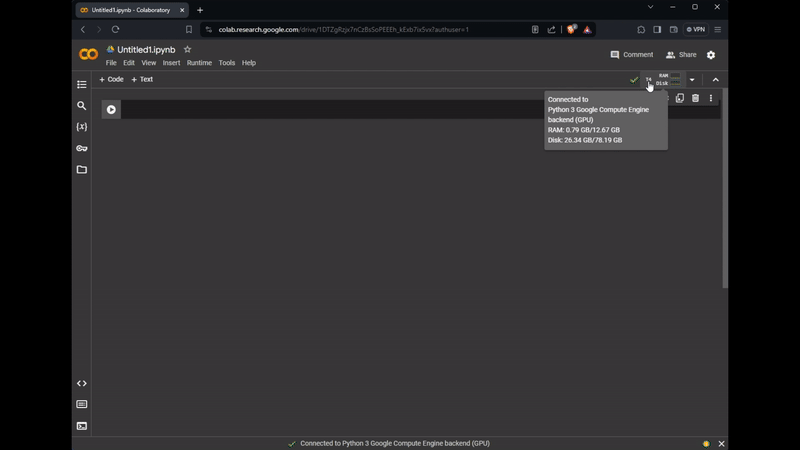
Change the runtime type and add GPU to your notebook. Image by the Author.
Step 1. Install Ollama and download AI LLM model
Ollama is a tool that allows to run open large language models locally (for example models such as LLaMA2, Mistral, LLaVa), equipped with a REST API for straightforward execution and management of these models.
Insert a new Code block into your notebook, paste the following commands, and execute it —as files required to run our model weigh ~8GB this might take 2–3 minutes:
#Install Ollama
!curl -fsSL https://ollama.com/install.sh | sh
#Run Ollama service in the background
!ollama serve &>/dev/null&
#Download LLaVA model (13b parameters, 1.6ver)
!ollama pull llava:13b-v1.6
Once successfully executed, we should see the following messages:
pulling 87d5b13e5157... 100% ▕▏ 7.4 GB
pulling 42037f9f4c1b... 100% ▕▏ 645 MB
pulling 41774062cd34... 100% ▕▏ 7.0 KB
pulling 9fb057c3f08a... 100% ▕▏ 45 B
pulling 7215dae26124... 100% ▕▏ 33 B
pulling 652f7b0bc7d4... 100% ▕▏ 565 B
verifying sha256 digest
writing manifest
removing any unused layers
success
Executing the above code block triggers the download of the official Ollama installer shell script, which is then executed. The second command initiates the Ollama service in the background, silencing all outputs by redirecting them to dev/null (both stdout and stderr).
The last command downloads the LLaVA multimodal model from the Ollama repository.
Multimodal models can understand and process information from various types of data (or modalities)— think text, images, and even sounds. In our example, we will use it to infer the content of the image provided to make it a bit more interesting than only sending text, but the same approach can be used to pull chat-optimized language open models such as Mistral, LLama2 or Gemma.
You can explore the available models in the Ollama Library, provided they are not too large for Colab’s free tier (typically, models up to 7B and some 13B models should work). Here’s the link to the library:
In this example, we use 13 billion parameter version of the model (13b), which for the LLaVA model aligns well with the free tier limits of Colab. If you’re willing to compromise on the model’s performance to save compute units or resources, consider experimenting with the 7 billion parameter version by changing 13b to 7b in ollama pull command.
At the time of writing this article, LLaVA 1.6 is the latest version of the model. This specific version is mentioned in the command provided above to prevent future regressions or changes that could impact notebook operation. If you wish to use the most recent model version, consider omitting the “-v1.6” from the command, which should automatically fetch the latest version available.
For readers curious about the flags used above, fun with flags - curl edition:
- -f [fail]: silently fail on errors,
- -s [silent]: silent mode with no progress output,
- -S [show-error]: show error messages in case of error,
- -L [location]: allows to follow server redirects to different URLs.
Step 2. Verify Colab’s Instance IP Address and Launch Localtunnel
In the following step, we’ll need to obtain the public IP address of our Colab runtime machine. Although it is technically optional, I strongly advise running the code provided below. Doing so enables us to verify later that our Ollama instance is functioning correctly.
#Check Colab's instance public IP address.
!curl ifconfig.me
The command mentioned sends HTTP request to ifconfig.me service, which then returns the public IP address from where the request originated — example response:
35.247.127.239
To share our model online, we require a mechanism that can make Colab’s localhost interface accessible on the internet via a public URL. For this purpose, we will utilize Localtunnel, a tool that allows making local web services available online for testing, demonstration, or development, without the need for deployment on a public server. To install and launch Localtunnel, we will add a code block with the following two commands:
#Download and install Localtunnel
!npm install localtunnel
#Run Localtunnel and redirect to localhost:11434
!npx localtunnel -p 11434
The commands above leverage the NPM package manager to install Localtunnel and then run it with the NPX package runner. By default, Ollama listens for incoming requests on port 11434, which is the same port we pass as an argument to Localtunnel to set up our tunnel.
Consequently, we’ll obtain a randomly generated URL where our service is now accessible. In my instance, it was:
npx: installed 22 in 1.225s
your url is: https://tiny-eyes-glow.loca.lt
Step 3. Check if Ollama Server is Running Properly and Accessible via URL
Let’s verify that everything is functioning correctly.
Open the URL provided in your browser; you’ll see Localtunnel’s security page:
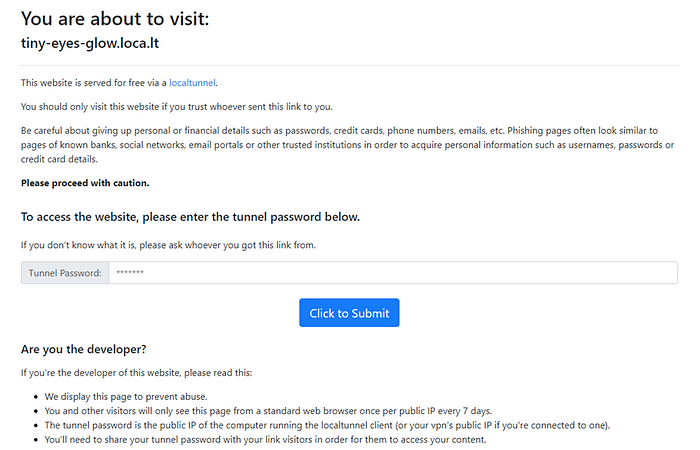
To proceed, you must enter the public IP address of our Colab runtime, which we obtained using the !curl ifconfig.me command in step 2 into the tunnel password field — in my case, that was 35.247.127.239.
Once we click to submit the address, we should see “Ollama is running” message, which means everything works as expected and we can start sending requests to our API endpoint.
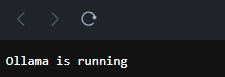
NOTE: This step can be skipped if your aim is to directly utilize the API. Localtunnel redirects only browser requests to its tunnel protection page. Direct requests from APIs will reach the Ollama API without requiring authentication.
Step 4. Interact with the Model Using Text Prompts and Images
It’s time to begin interacting with our model. For this demonstration, we’ll use a Python script to communicate with the model via the Ollama API.
Our final solution should look like this:
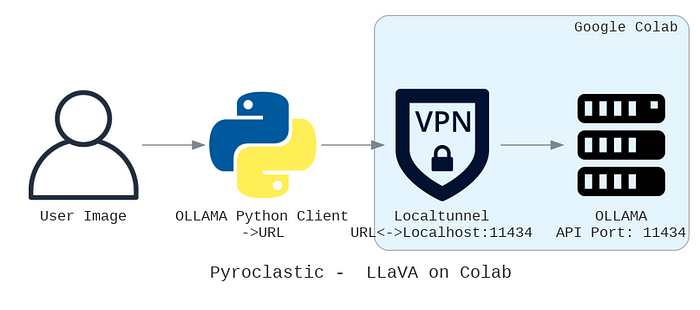
Proceed by creating a new Colab notebook for our client Python script (or create it on your local machine if you have a local IDE/Python installed), and add the code block below to install the Ollama Python API:
#Install Ollama python package
!pip install ollama
Now add a new code block below and input the Python script provided below — make sure to replace the host URL with the one Localtunnel provided earlier:
from ollama import Client
#Replace the URL with your localtunnel URL
host = 'https://tiny-eyes-glow.loca.lt/'
# Initialize the Ollama client.
ollama_client = Client(host)
# Prepare the message to send to the LLaVA model.
message = {
'role': 'user',
'content': 'What is in this picture?',
'images': ['/9j/4AAQSkZJRgABAQEAYABgAAD/4QAiRXhpZgAATU0AKgAAAAgAAQESAAMAAAABAAEAAAAAAAD/2wBDAAIBAQIBAQICAgICAgICAwUDAwMDAwYEBAMFBwYHBwcGBwcICQsJCAgKCAcHCg0KCgsMDAwMBwkODw0MDgsMDAz/2wBDAQICAgMDAwYDAwYMCAcIDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAz/wAARCAAcAAoDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwDv7jwn5OqWEeGXzjKMAcHameav/wDCE/7H6V1/jFNL0L4l+EdNuri3hvL95/Jjd9pbcmwfm3Az1Ndv/wAIUB/yz/Sv3fD5nF1KqT2kv/SYn5DiMLNU6Urbxf8A6UzzH4meLm8WfEfVrjTdGbVLrw+IbfTLyEyMllLBL50zPhP4vukDOFGe9ezaH8XvDWuaLZ3v9q2cf2yBJ9gbhNyhsc4PGe4Br6F+Gf8AwSY+GvwVso7DwzrHj/TbCzkuLuO3/tvzVE84CyybnQsCyqF2hgmP4c81yFx/wQh+BN3cSSt/wnStIxchfEMiqCeeABgD2r8Kp8QYynOU4297f8+3mfqVfK8JUhCDjsv6/LyP/9k=']
}
# Use the ollama.chat function to send the image and retrieve the description.
try:
response = ollama_client.chat(
model = "llava:13b-v1.6", # Specify LLaVA model size and version hosted
messages = [message]
)
except ollama_client.ResponseError as e:
print('Error:', e.error)
# Print the model's description of the image
response = response['message']['content']
print(response)
The script includes an example of a base64 encoded image passed as the ‘images’ parameter and sent to the model. Alternatively, this parameter can be a path to a local file on your PC (or file uploaded to the Colab Notebook).
Now execute both code blocks — for the image included in the example, the model should respond with something similar to: “The image shows the Eiffel Tower, a famous landmark in Paris, France. The photo appears to be taken during the day with clear skies, and there’s a blurred background that might suggest movement or an out-of-focus area.”
Closing Thoughts and Complete Code Notebooks
I hope you found the above example interesting. In my upcoming article, I’ll explore further how we can leverage this approach to tackle various use cases enabled by open models and open-source software.
Some considerations regarding using Google Colab:
- Colab’s free tier permits notebooks to operate for up to 12 hours and supports running two sessions simultaneously,
- To conserve resource units/sessions, it’s advisable to run the notebook only during experimentation or development phases with your model,
- While the free tier accommodates smaller models from the Ollama library, the same code can facilitate hosting larger models using paid tiers,
- The method described is intended for experimental and development purposes only and is not suitable for production environments, even with paid tiers.
Now you can access complete Google Colab notebooks on the project’s GitHub repository:
https://github.com/gitbarlew/Pyroclastic---LLaVA-Cloud/tree/main
- Colab Server Side: https://github.com/gitbarlew/Pyroclastic---LLaVA-Cloud/blob/main/Pyroclastic_Run_LLaVA_on_Google_Colab.ipynb
- Python Client Side: https://github.com/gitbarlew/Pyroclastic---LLaVA-Cloud/blob/main/LLaVA_Query_Example.ipynb
- Diagram: https://github.com/gitbarlew/Pyroclastic---LLaVA-Cloud/blob/main/Pyroclastic_diagram.ipynb
If you’ve found these insights helpful or inspiring, consider:
- Following me on LinkedIn: https://www.linkedin.com/in/barteklewicz/
- Starring my GitHub repository: https://github.com/gitbarlew
- Buying Me a Coffee: https://www.buymeacoffee.com/bartlomiejw
Your engagement and support mean the world to me. It encourages me to continue sharing my knowledge and experiences, contributing to a community passionate about AI and technology. Let’s stay connected and keep the conversation going!
References:
- Localtunnel GitHub repository: https://github.com/localtunnel/localtunnel
- Ollama homepage: https://ollama.com/
- Ollama LLaVA Library: https://ollama.com/library/llava:v1.6
- LLaVA GitHub repository: https://llava-vl.github.io/
#Colab #LLM #AI #Models #CloudDeployment #FreeTier #API #Localtunnel #Ollama #MultimodalAI #LLaVA #Google #OpenModels #OpenSource #ExperimentalDevelopment #ColabNotebooks #PythonScripting #ModelDeployment
Cubed
Write about the technologies shaping the future.
For developers, founders, and curious minds exploring AI, crypto, Web3, and emerging tech—signal over noise.
One free account across In Plain English, Stackademic, Venture, and Cubed.
How it works- AI, crypto & Web3
- Software & emerging technologies
- Analysis & practical resources
- Thoughtful voices, not hype
Sign in
Google or GitHub
Complete profile
Takes a few minutes
Get approved & publish
Start sharing
Why write for Cubed?
The future deserves thoughtful voices, not just louder headlines.




Comments
Loading comments…