Large language models (LLMs) have taken the world by storm. Their ability to generate human-quality text for a variety of tasks is truly impressive. However, LLMs still struggle with limitations, particularly around context and factual accuracy. This is where Retrieval-Augmented Generation (RAG) steps in.
The original RAG model aimed to address these shortcomings by feeding relevant information retrieved from external sources directly to the LLM. This approach showed promise, but there were limitations. The creators of RAG have addressed these issues with the introduction of RAG 2.0.
What is RAG 2.0?
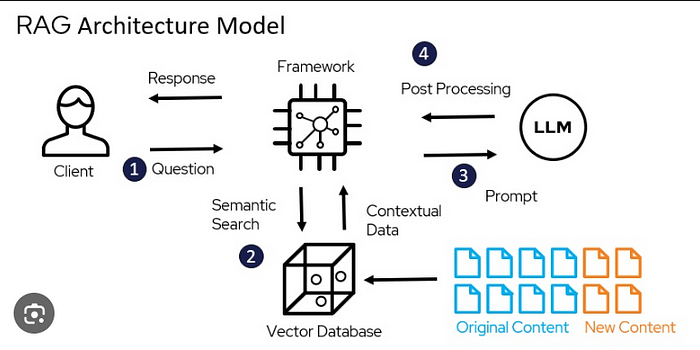
RAG 2.0 builds upon the core idea of RAG 1.0 — enriching the LLM’s capabilities by providing relevant external information. However, it introduces several key improvements:
- Improved Retrieval Strategy: RAG 1.0 relied on a basic retrieval method. RAG 2.0 utilizes a more sophisticated approach that considers not just keywords, but also the semantic similarity between the prompt and retrieved passages. This ensures the retrieved information is truly aligned with the context of the task.
- Flexible Data Integration: RAG 1.0 required storing retrieved information alongside the training data for the LLM. This could be cumbersome and limited the type of data that could be integrated. RAG 2.0 allows for on-the-fly retrieval during inference. This opens the door to using a much wider range of external sources, including constantly updated databases and knowledge graphs.
- Privacy-Preserving Architecture: A major concern with RAG 1.0 was the need to share training data with the LLM provider. This could be a dealbreaker for companies with sensitive information. RAG 2.0 offers a privacy-preserving architecture that allows companies to keep their data on-premise while still benefiting from RAG’s capabilities.
The Potential Impact of RAG 2.0
These advancements hold significant promise for the future of LLMs. Here are some potential benefits:
- Enhanced Factual Accuracy: By providing access to reliable external information, RAG 2.0 can significantly improve the factual accuracy of LLM outputs. This is crucial for tasks like summarizing research papers or generating reports.
- Deeper Contextual Understanding: The ability to retrieve and integrate relevant information allows LLMs to develop a deeper understanding of the context surrounding a prompt. This can lead to more nuanced and informative responses, particularly in complex tasks.
- Improved Reasoning and Decision-Making: By leveraging external knowledge, LLMs with RAG 2.0 could potentially be used for tasks that require reasoning and decision-making abilities. This opens doors to applications in areas like healthcare and finance.
- Democratizing Access to Powerful LLMs: The privacy-preserving architecture of RAG 2.0 allows companies to leverage the power of LLMs without compromising on data security. This could democratize access to these advanced tools for a wider range of organizations.
Is RAG 2.0 a Silver Bullet?
While RAG 2.0 represents a significant step forward, it’s important to maintain realistic expectations. Here are some points to consider:
- Data Quality Matters: The effectiveness of RAG 2.0 hinges on the quality and relevance of the retrieved information. Careful curation of external data sources is crucial.
- Computational Cost: Integrating retrieval and processing external data adds complexity to the LLM pipeline. This can lead to increased computational costs, which need to be factored in.
- Integration Challenges: Implementing RAG 2.0 requires expertise in both LLMs and information retrieval systems. This can present a challenge for some organizations.
The Future of RAG and LLMs
RAG 2.0 represents a significant step forward in the evolution of LLMs. By providing a more robust and flexible way to incorporate external knowledge, it opens doors to a wider range of applications and improved performance. However, it’s important to view RAG 2.0 as a tool that complements, rather than replaces, the advancements being made in LLM architectures themselves. As both LLMs and retrieval techniques continue to develop, we can expect even more impressive capabilities to emerge in the future.
More in rag
Cubed
Write about the technologies shaping the future.
For developers, founders, and curious minds exploring AI, crypto, Web3, and emerging tech—signal over noise.
One free account across In Plain English, Stackademic, Venture, and Cubed.
How it works- AI, crypto & Web3
- Software & emerging technologies
- Analysis & practical resources
- Thoughtful voices, not hype
Sign in
Google or GitHub
Complete profile
Takes a few minutes
Get approved & publish
Start sharing
Why write for Cubed?
The future deserves thoughtful voices, not just louder headlines.



Comments
Loading comments…