
In the ever-evolving landscape of artificial intelligence, the quest for faster and more efficient language models (LMs) has been a driving force. Recently, a groundbreaking advancement has emerged in the form of Gro, a platform revolutionizing LM inference speed. Gro's innovative approach, fueled by dedicated hardware known as Language Processing Units (LPUs), has ushered in a new era of rapid text generation, showcasing unprecedented speeds that defy conventional GPU-based inference methods. This article delves into Gro's technology, its implications for various industries, and the transformative potential it holds for the future of AI applications.
Gro's Inference Speed
Gro's exceptional speed in LM inference stems from its utilization of LPUs, specialized hardware designed explicitly for processing language-based tasks. In contrast to traditional GPUs, which were originally developed for graphics processing and later repurposed for AI, LPUs offer superior compute density and memory bandwidth tailored specifically for sequential text generation tasks. This strategic architecture enables Gro to achieve remarkable speeds, as demonstrated by its ability to generate nearly 500 tokens per second, surpassing the capabilities of leading competitors such as GPT-4 and Mixr by significant margins.
Below Image is Inference Speed (Tokens/sec) on Various platforms for 70B

https://github.com/ray-project/llmperf-leaderboard
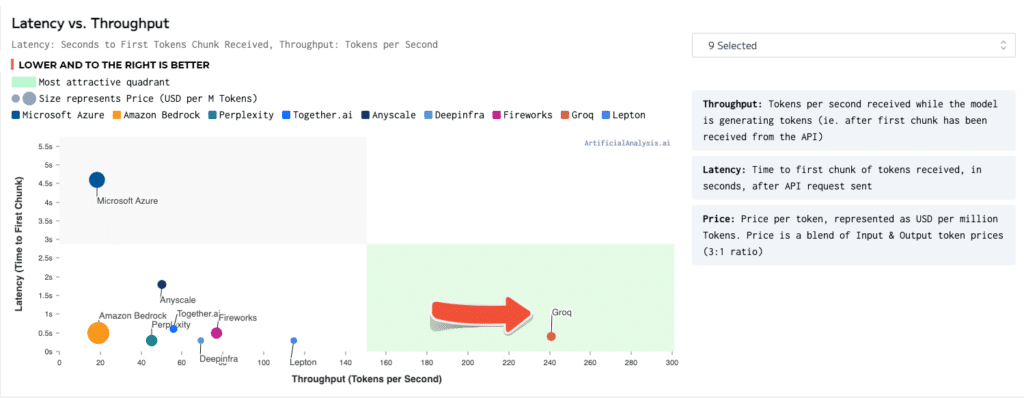
Latency vs Throughput
- Latency: Time to first tokens chunk received, in seconds, after API request sent
- Throughput: Token per second received while the model is generating tokens (ie after the first chunk has been received from the API)
- Lower and to the right is better, with the green representing the most attractive quadrant
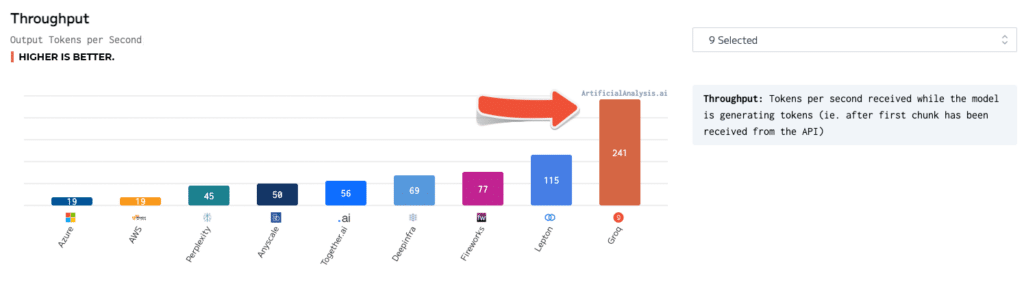
Throughput
- Throughput: Token per second received while the model is generating tokens (ie after the first chunk has been received from the API)
- Higher is better
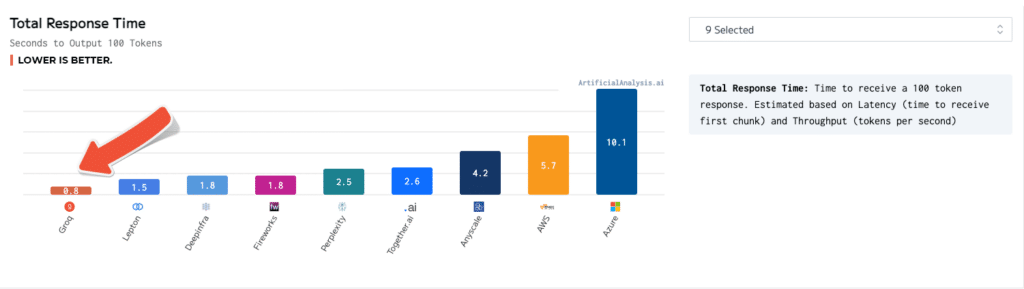
Total Response Time
- Total response time: Time to receive a 100 token response, estimated based on latency and throughput
- Lower is better
Understanding LPUs
LPUs represent a paradigm shift in LM processing, providing unparalleled efficiency and speed for computationally intensive language tasks. By optimizing compute density and memory bandwidth, LPUs outperform conventional GPUs and CPUs, particularly in scenarios requiring rapid text generation. Unlike GPUs, which excel in parallelized computations, LPUs prioritize sequential processing, making them ideal for LM inference where sequence generation is paramount.
Implications for Industries
The implications of Gro's accelerated inference speed are vast and far-reaching, with potential applications across various industries. In sectors such as real-time language translation, transcription services, and automated emergency systems, where milliseconds can mean the difference between success and failure, Gro's rapid text generation capabilities offer unprecedented advantages. Additionally, in fields like algorithmic trading and conversational AI, where speed is paramount for decision-making and user interaction, Gro's performance enhancements open doors to new possibilities and optimizations.
API Access and Pricing

GROQ : https://wow.groq.com/
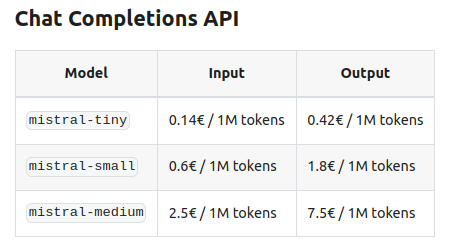
Mistral : https://docs.mistral.ai/platform/pricing/

Anthropic : https://www-cdn.anthropic.com/31021aea87c30ccaecbd2e966e49a03834bfd1d2/pricing.pdf

OpenAI : https://openai.com/pricing#language-models
Gro's API access provides developers and organizations with the opportunity to leverage its lightning-fast inference capabilities for their projects. With access to models like Lama 270 Billion and Mix from Mistral AI, users can experience firsthand the transformative power of Gro's technology. Moreover, Gro's competitive pricing model ensures accessibility, offering rates significantly lower than traditional alternatives while guaranteeing superior performance.
Future Outlook
As Gro continues to push the boundaries of LM inference speed, the future of AI applications looks brighter than ever. With LPUs at the forefront of innovation, the possibilities for real-time language processing, conversational AI, and beyond are limitless. As more industries embrace Gro's technology, we can expect to see a proliferation of AI-driven solutions that were once deemed unattainable due to speed constraints. Ultimately, Gro's ascent marks a pivotal moment in the evolution of language models, heralding a new era of efficiency, accessibility, and innovation in AI.
In conclusion, Gro's groundbreaking advancements in LM inference speed represent a game-changer for the AI industry. By leveraging dedicated hardware in the form of LPUs, Gro has redefined the boundaries of what's possible, ushering in a new era of rapid text generation and real-time language processing. As businesses and developers embrace Gro's technology, we stand on the precipice of a transformative shift in AI applications, where speed, efficiency, and performance converge to unlock unprecedented possibilities for innovation and advancement.
Thank you for reading, I hope this article keeps you updated.
Cubed
Write about the technologies shaping the future.
For developers, founders, and curious minds exploring AI, crypto, Web3, and emerging tech—signal over noise.
One free account across In Plain English, Stackademic, Venture, and Cubed.
How it works- AI, crypto & Web3
- Software & emerging technologies
- Analysis & practical resources
- Thoughtful voices, not hype
Sign in
Google or GitHub
Complete profile
Takes a few minutes
Get approved & publish
Start sharing
Why write for Cubed?
The future deserves thoughtful voices, not just louder headlines.

Comments
Loading comments…